在人工智能领域的最新一轮竞争中,百度成为了外界关注的焦点。尽管外界对其是否减缓步伐存在质疑,但从百度的实际行动来看,其在大模型赛道上的每一步都透露出野心与决心。
2025年初,DeepSeek-R1的横空出世,无疑给中国的大模型竞争格局带来了巨大震动。此前,行业普遍认为AI大模型是科技巨头的专属游戏,创业公司难以涉足。然而,DeepSeek的崛起不仅打破了这一共识,还引发了一系列连锁反应,推动了大模型竞争焦点的转变。

DeepSeek的出现,不仅让大厂重新感受到了紧迫感,也促使它们调整AI战略,更加积极地拥抱AI大模型的应用落地。在此背景下,阿里、字节跳动等巨头迅速推出了对标DeepSeek的新模型,加速布局AI应用生态。
百度,作为曾一度领跑中国大模型市场的玩家,面对DeepSeek的冲击,其应对策略备受瞩目。尽管在外界看来,百度的反应似乎不够迅速,但百度在大模型赛道上的布局并未停滞。
在4月25日的百度开发者大会上,百度终于亮出了自己的底牌。百度不仅发布了文心大模型4.5 Turbo和文心大模型X1 Turbo两款升级版大模型,还推出了一系列新款AI应用,包括高说服力数字人、多智能体协作应用“心响”等,展示了其在模型、应用和算力三个方向的全面布局。
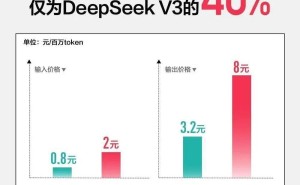
百度创始人李彦宏在大会上强调,当前开发者做AI应用的一大阻碍是大模型成本高。为了降低开发者的门槛,百度此次发布的两款新模型主打多模态、强推理、低成本三大特性,定价远低于市面上其他主流模型。
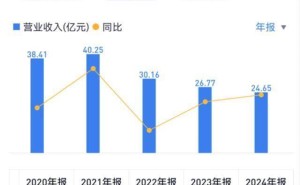
百度在大模型领域的坚持长期投入,已经取得了显著成效。数据显示,百度文心大模型的日均调用量在快速增长,增速远超市场大盘。同时,百度的云业务也受益于大模型的发展,业绩实现了快速增长。
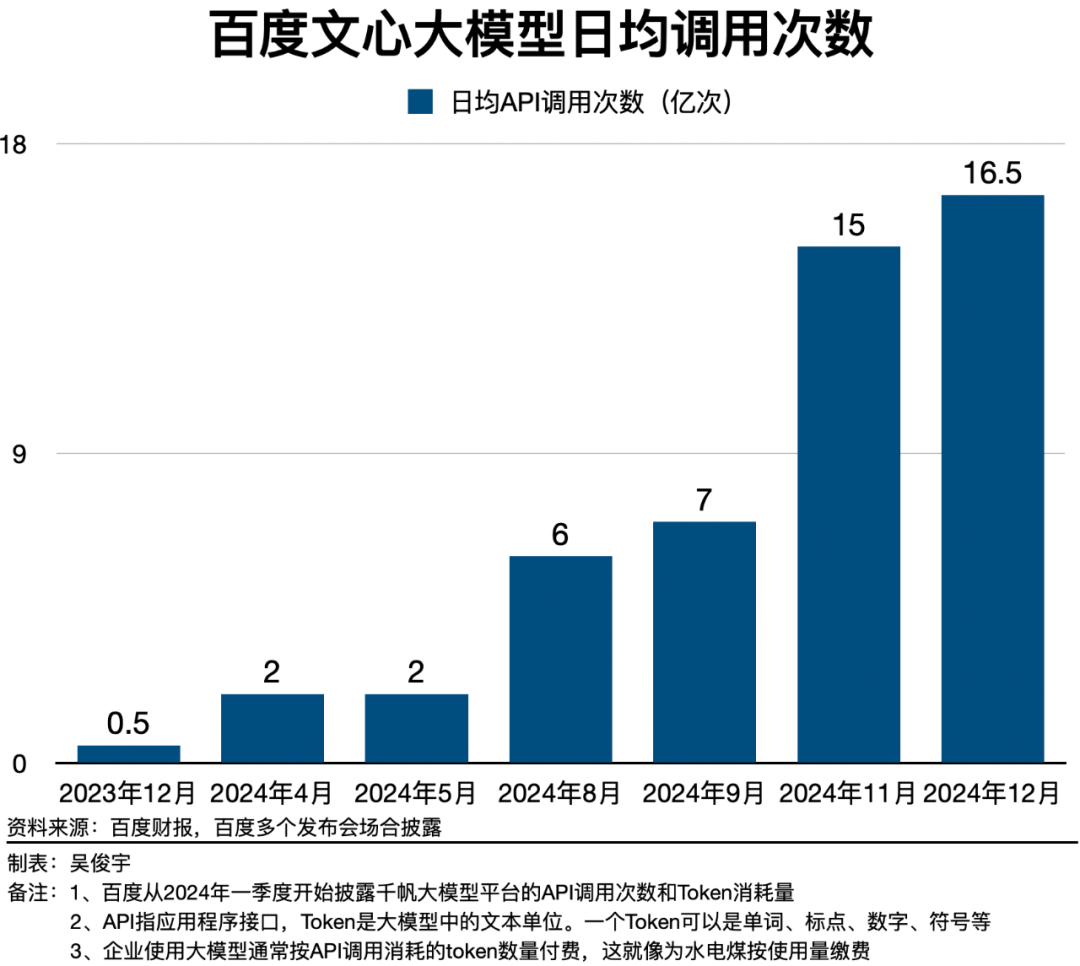
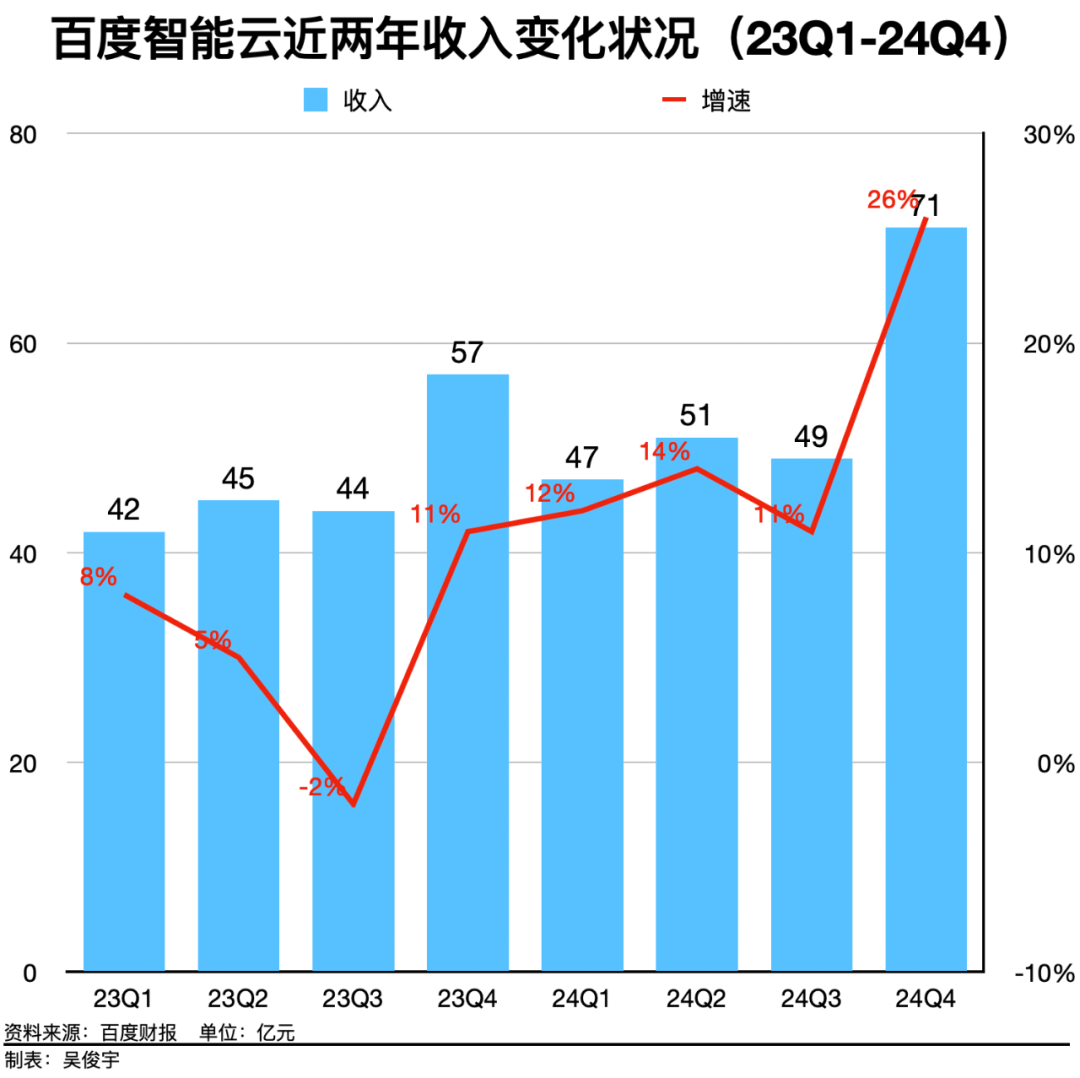
值得注意的是,百度在大模型策略上也进行了调整,从过去的闭源转向开源。这一转变不仅有助于扩大文心大模型的影响力,还能刺激市场需求,带动算力消耗和收入增长。
随着推理算力成本的不断下降,2025年AI应用爆发的趋势已经愈发明显。百度正在拥抱这一趋势,不仅在重点AI应用赛道进行布局,还在帮助开发者降低AI应用的开发门槛。通过兼容MCP开放标准、优化开发工具、布局重点应用赛道以及提供应用分发和收益分成机制等措施,百度正在积极推动AI应用的广泛落地。
面对算力断供的风险,百度也在积极寻求应对策略。通过自研算力和工程优化等方式,百度正在打破算力瓶颈、降低算力成本。百度昆仑芯三代P800芯片的超节点方案以及一系列软硬件工程手段的应用,都展现了百度在算力领域的创新实力。
在新一轮AI卡位战中,百度用实际行动证明了自己的实力和决心。尽管外界对其存在质疑,但百度在大模型赛道上的每一步都走得坚定而有力。