百度AI开发者大会:李彦宏强调应用为王,多模态与智能体成焦点

在春意盎然的四月,百度于武汉盛大召开了Create 2025百度AI开发者大会,汇聚了众多AI领域的精英与开发者。会上,百度创始人李彦宏发表了题为“模型的世界,应用的天下”的主旨演讲,深入探讨了AI模型与应用之间的关系,以及多模态与智能体的发展趋势。
李彦宏指出,尽管AI模型迭代迅速,但真正的价值在于应用。他强调,没有应用,再先进的模型也只是空中楼阁。在AI技术日新月异的今天,开发者们需要找对场景、选对模型,甚至学会调整模型,以此为基础开发的应用才能经得起时间的考验。
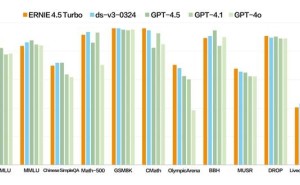
针对近期备受瞩目的DeepSeek模型,李彦宏表示,百度各业务线正在积极接入,但DeepSeek并非万能。目前,它仅能处理文本信息,对于图片、音频、视频等多媒体内容的理解和生成尚存在局限。DeepSeek的幻觉率较高,且运算速度慢、成本高。李彦宏预测,多模态将成为未来基础模型的标配,纯文本模型的市场将逐渐萎缩。
在演讲中,李彦宏特别提到了代码智能体Coding Agent这一赛道,认为未来每个公司都将依赖代码智能体来完成任务。他将基于MCP(模型上下文协议)开发智能体比作2010年开发移动APP,并表示百度将积极推动更多应用和服务接口兼容MCP,以赋能开发者创新。
李彦宏通过实例进一步阐释了应用的价值。在交通领域,部署在高速路侧的边缘系统中的小模型虽然能够检测安全事件,但识别准确率有限,误报、漏报现象时有发生。而借助云端的大模型进行秒级校验,可以显著提高检测准确率,降低监控人员的工作量。李彦宏认为,随着模型能力的增强,AI应用将渗透到更多场景,创造更大的价值。
为了满足开发者对低成本、高性能模型的需求,百度在大会上正式发布了文心大模型4.5 Turbo和文心大模型X1 Turbo。这两款模型主打多模态、强推理、低成本三大特性,旨在解决DeepSeek等模型存在的问题。文心大模型4.5 Turbo的输入价格仅为每百万token 0.8元,输出价格为3.2元,相比文心4.5速度更快,价格下降80%。文心大模型X1 Turbo的输入价格为每百万token 1元,输出价格为4元,性能提升的同时价格再降50%。
李彦宏表示,不断降低大模型的成本是推动AI应用爆发的关键。成本降低后,开发者和创业者们可以放心大胆地做开发,企业也能够低成本地部署大模型。这将促进各行各业AI应用的快速发展。
李彦宏还介绍了百度在智能体领域的最新进展。他提到,智能体已经成为AI应用的代名词,而代码智能体Coding Agent更是近半年来进展最快、最火的赛道。百度的工程师普遍使用文心快码Comate等辅助代码生成工具,非技术人员则倾向于使用秒哒等无代码编程工具。秒哒拥有无代码编程、多智能体协作、多工具调用三大特性,已经向社会全面开放。
李彦宏强调,未来的AI应用不仅需要能够回答问题,还要能够完成任务。而复杂任务的交付需要多智能体协作来解析需求、分拆任务、调度资源、规划执行。基于MCP开发智能体将大大降低开发难度和提高效率。百度将持续加大对MCP的支持,推动更多应用和服务接口兼容MCP,共建繁荣的MCP生态。
在大会的最后,李彦宏总结了百度在模型和应用方面的九大发布,包括文心大模型4.5 Turbo和X1 Turbo的发布、高说服力数字人、沧舟OS系统、代码智能体秒哒的新进展、多智能体协作APP心响等。这些发布旨在让开发者们可以无忧无虑地专注于应用开发,创造出真正优秀的应用。