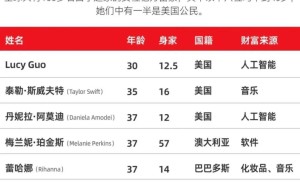
在今日于武汉盛大举行的百度Create开发者大会上,百度创始人兼首席执行官李彦宏带来了震撼业界的消息。他正式揭晓了百度最新的技术成果——文心大模型4.5 Turbo与文心大模型X1 Turbo。
李彦宏在大会上深刻剖析了当前AI模型市场的现状,指出诸如DeepSeek等模型虽备受瞩目,但仍存在模态单一、幻觉率高、运行速度慢及成本高昂等问题。正是为了应对这些挑战,百度推出了这两款全新升级的大模型。
他提到,随着DeepSeek的崛起,MCP(模型上下文协议)逐渐成为行业标准,代码智能体、通用智能体等多智能体协作产品日益受到关注,开源中国社区在过去一年内新增了150万开发者。然而,面对模型迭代迅速、能力日益强大的现状,不少开发者感到焦虑,担心基于大模型开发的应用很快过时,失去价值。
“大模型领域日新月异,每周都有新发布,每天都有更新。去年第四季度有49个大模型更新发布,今年一季度更是达到了55个,最繁忙的一周甚至发布了8个模型。”李彦宏说道。他指出,这种快速迭代对于开发者而言是双刃剑,既需要紧跟技术趋势,又要找对场景、选对基础模型。
李彦宏强调,AI应用才是创造真正价值的所在,没有应用,模型和芯片都失去了意义。他回顾了早前的观点,指出中国存在过多的大模型,其中大部分使用量有限,这是对社会资源的极大浪费,更多资源应投入到超级应用中。
关于开源与闭源模型的争论,李彦宏再次表明立场。他认为,在商业领域,追求效率和效果时,开源模型并无优势。他提到,DeepSeek虽强,但存在局限性,如只能处理文本,无法理解多模态内容,幻觉率高,且调用价格昂贵。相比之下,百度新推出的文心大模型4.5 Turbo和X1 Turbo在速度和成本上均有显著优势。
文心大模型4.5 Turbo相比文心4.5,速度更快,价格下降80%,每百万tokens的输入价格仅为0.8元,输出价格为3.2元,仅为DeepSeek-V3的40%。而文心大模型X1 Turbo的调用价格更为亲民,仅为DeepSeek R1的25%,输入价格为1元/百万tokens,输出价格为4元/百万tokens。
李彦宏还公布了百度基于昆仑芯三代P800打造的中国首个全自研3万卡集群,该集群能够同时承载多个千亿参数大模型的全量训练,并支持1000个客户进行百亿参数大模型的精调。
李彦宏在演讲的尾声充满信心地表示:“现在,在中国开发应用,我们有底气。我们坚信,应用创造未来,开发者创造未来。”这一席话,不仅为开发者们指明了方向,也彰显了百度在AI领域的雄厚实力和坚定决心。