在人工智能领域的喧嚣中,朱松纯以其独特的视角成为了少数派的一员。
他深信,科学的真谛在于用简洁的模型揭示复杂现象的本质。诸如杨振宁、爱因斯坦等科学巨匠,他们构建的理论框架往往仅包含寥寥几个参数。反观当下的大模型,动辄拥有百亿、千亿级别的参数,且难以解释其运作机制。“从这一视角审视,它们的确显得相当笨拙。”朱松纯坦言。
然而,他也承认,从工程实践的角度来看,大模型在某些特定任务上确实能够取得不俗的表现。
近期,朱松纯与北京通用人工智能研究院(通研院)及北京大学的多位学者共同编纂了《通用人工智能标准、评级、测试与架构》一书,为通用人工智能领域提出了全面的标准、评级、测试与架构体系,该体系同样适用于大模型。
书中提出的评测体系对智能的定义更为严格。一个智能体不仅要能够完成任务,还需具备自主定义任务的能力。这意味着,智能体无法像在其他评测体系中那样,通过针对性地优化来“刷榜”。
回顾过去二十年,刷榜几乎成为了人工智能发展历程上的一个标签。朱松纯也曾是这一潮流中的一员。2004年,他与全球计算机领域的顶尖科学家沈向洋在湖北共同创立了莲花山研究院,成为最早大规模从事大数据标注的机构之一。
然而,随着对通用泛化任务理解的深入,朱松纯开始意识到,刷榜的方法可能是一条死胡同。因为通用泛化任务本质上是一个无穷无尽的任务集合。例如,训练一个机器人学会抓取杯子可能很容易,但一旦杯子的位置、重量或尺寸发生变化,机器人就可能无法识别。
在打破了对刷榜的迷信后,朱松纯开始探索新的道路。2017年,他提出了“小数据、大任务”范式,其核心在于“为机器赋予心灵”,让智能体能够自主地构建物理世界的感知。

在这一理论框架下,通研院仅用10张显卡就训练出了由价值和因果驱动的智能体“通通”。截至今年,“通通”的智商和情商已相当于一个五岁左右的小女孩,能够一定程度上理解周围环境,并拥有自己的个性,甚至会耍赖、撒谎。
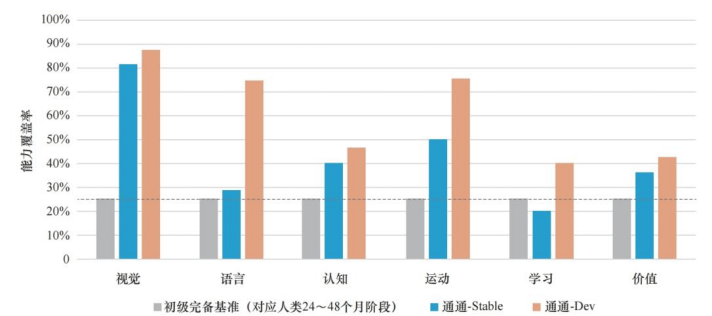
相比之下,一些大模型在特定领域如司法考试、数学、编程、法律等方面的表现已接近人类博士的平均水平,甚至在医学考试中的正确率超过了大多数医学博士考生。然而,朱松纯认为,这些能力更多地属于专业能力而非通用泛化能力。大模型给出的答案可能是猜测、刷题或死记硬背的结果。而拥有认知架构的通用智能体,尽管目前可能显得幼稚,但却具备自主性和成长性。
朱松纯多次强调,中国需要形成自己的AI叙事,不能盲目追随硅谷的模式,仅仅依靠堆算力和数据。他呼吁中国要找到一条适合自己的路线,进行原创性研究。
在搜狐科技的采访中,朱松纯进一步阐述了他对大模型态度的转变。他表示,虽然从科学的角度来看,大模型显得笨拙且难以解释,但从工程实践的角度来看,它们确实能够产生一定的效果。
当被问及为何将大模型纳入评测体系时,朱松纯指出,评测体系需要涵盖所有类型的智能体。从目前的测试结果来看,大模型的效果并不理想。
针对“小数据、大任务”范式所遭受的质疑,朱松纯表示,这些质疑往往来自于习惯于刷榜的科研人员。他强调,追求简约和美的科学本质并未改变,这也是他们提出CUV架构(认知架构、价值函数和效用函数)的初衷。