字节跳动旗下的Seed实验室近日震撼发布了其最新一代多模态智能体——UI-TARS-1.5,并大方地将源代码向公众开放。这款智能体以视觉-语言模型为核心,专为虚拟世界中的高效任务执行而设计,相较于上一代,其高阶推理能力得到了显著提升。
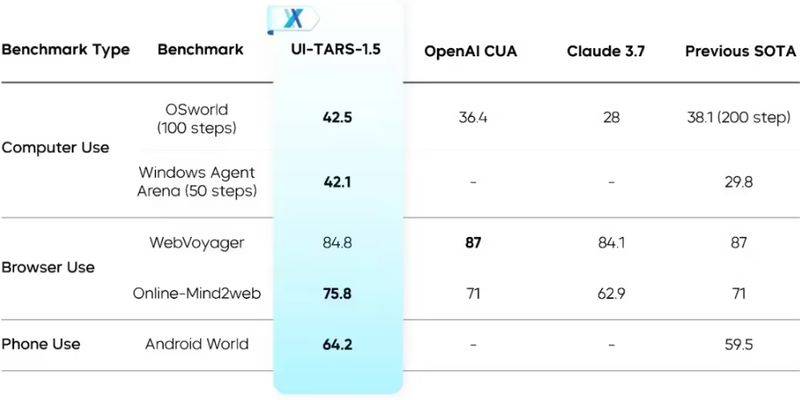
UI-TARS-1.5是在字节跳动早前推出的原生智能体方案UI-TARS的基础上,融合了强化学习技术,从而极大地增强了其推理能力。这一改进使得智能体在执行任务前能够进行更为周密的思考,有效规划行动步骤,从而大幅提升任务执行的效率和准确性。
UI-TARS-1.5的强大实力源自四大核心技术创新:
首先,视觉感知能力得到了全面增强。通过大规模界面截图数据的训练,智能体能够深入理解和分析界面元素的语义及上下文信息,实现对界面元素的精准描述,为后续决策提供坚实的信息支撑。
其次,引入了System 2推理机制。这一机制让UI-TARS-1.5在执行动作前能够生成“思考”,支持对复杂任务进行多步骤规划和决策,模拟人类的深思熟虑过程,大大提升了其处理复杂任务的能力。
再者,统一动作建模技术的运用,通过构建跨平台的标准动作空间,并结合真实轨迹学习,使得UI-TARS-1.5能够更精确地控制动作的执行,提高了动作的可控性和精确度。
最后,UI-TARS-1.5采用了可自我演化的训练范式。通过自动化的交互轨迹采集和反思式训练机制,智能体能够不断从错误中学习,持续改进自身,以适应复杂多变的任务环境。
UI-TARS-1.5的研发团队还提出了一个创新性的愿景:利用游戏作为载体来增强基础模型的推理能力。相较于数学、编程等专业领域,游戏更多地依赖于直观的、常识性的推理,对专业知识的依赖较少,因此成为评估和提升未来模型通用能力的理想测试平台。
UI-TARS-1.5不仅仅是一个理论上的智能体,更是一个具备实际操作能力的“数字助手”。作为原生GUI智能体,它能够真实地操控电脑和系统,操作浏览器,并顺利完成各种复杂的交互任务,展现了其在现实应用中的巨大潜力。