字节跳动近期在人工智能领域取得重要突破,其Seed研究团队推出了一款名为VAPO的强化学习训练框架,旨在增强大型语言模型在复杂、冗长任务中的推理能力。
在大型语言模型的强化学习训练中,价值导向方法因其能够精确追踪每个动作对后续回报的影响而备受瞩目。然而,在应用于长链式推理任务时,价值模型面临初始化偏差、序列长度差异适应困难以及奖励信号稀疏等挑战,这些问题限制了价值导向方法的应用效果。
为解决这些难题,字节跳动推出了VAPO框架,全称为增强价值的近端政策优化。该框架基于PPO算法,并引入了三项创新技术。
首先,VAPO构建了一个精细的价值训练框架,提升了模型对复杂任务的理解能力。其次,引入了长度自适应广义优势估计机制,该机制能够根据响应长度动态调整参数,从而优化长短序列的训练效果。最后,VAPO整合了多项先前的研究技术,形成了一个协同增效的系统。
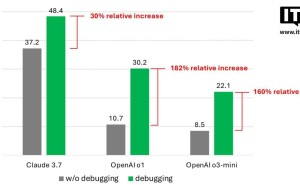
在实验中,Qwen2.5-32B模型通过VAPO优化后,在AIME24基准测试中的得分从5分飙升至60.4分,这一成绩不仅超越了DeepSeek R1的47分,还超过了此前业界领先的DAPO方法的50分,而且仅用了60%的更新步骤就达到了这一水平。
与传统PPO算法相比,VAPO在数学推理能力上有了显著提升,训练曲线更加平滑,优化过程也更加稳定。特别是在长序列任务中,VAPO表现出色,得分增长迅速。这主要得益于其价值模型提供的细粒度信号。
VAPO的成功离不开其综合优化设计。消融研究表明,七项关键技术对VAPO的性能提升起到了关键作用。其中包括价值预训练防止模型崩溃、解耦GAE支持长回答优化、自适应GAE平衡短长回答、剪裁策略鼓励探索、词级损失增加长回答权重、正例语言模型损失提升以及分组采样等。
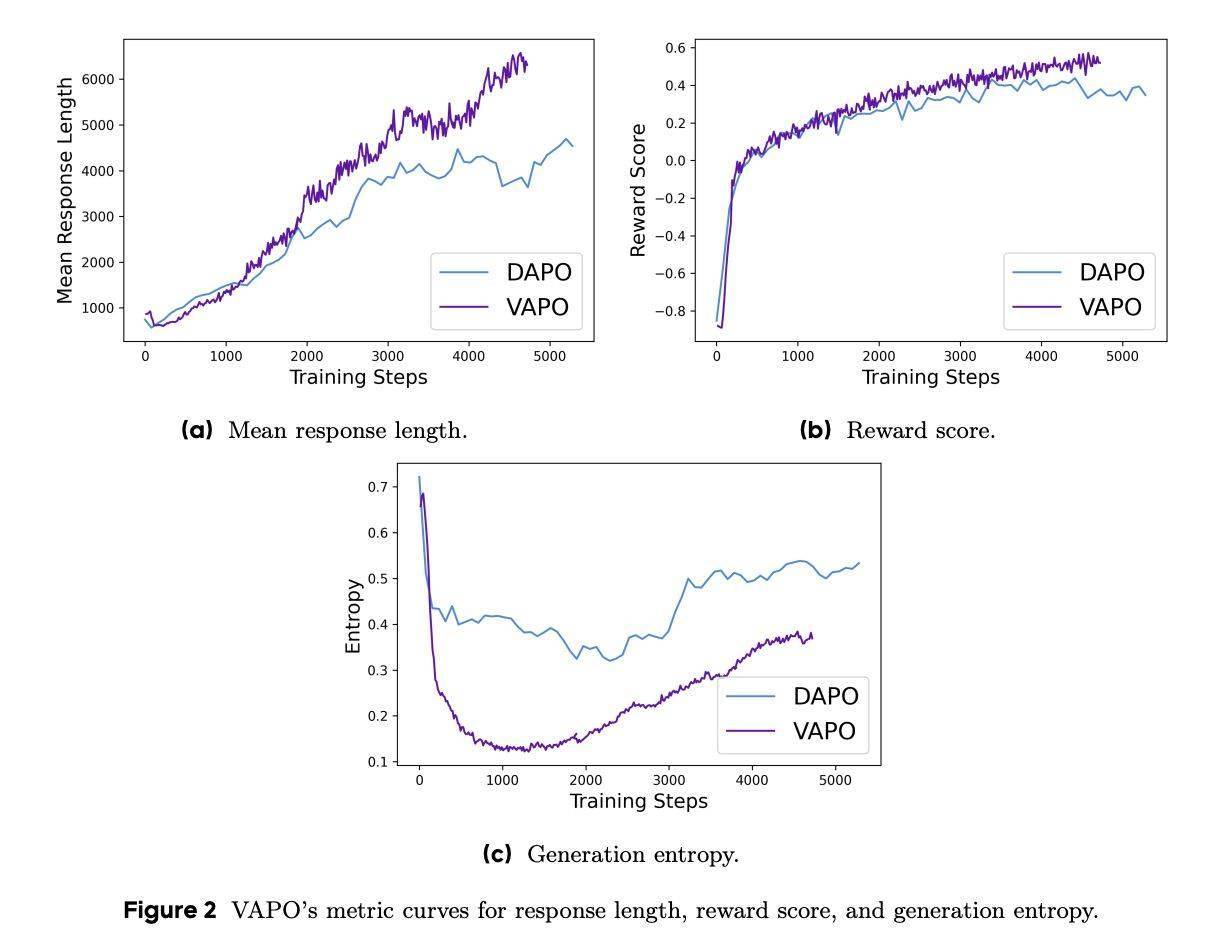
这些改进使得VAPO在探索与利用之间找到了最佳平衡,显著优于无价值导向的GRPO和DAPO方法。VAPO不仅提升了数学推理能力,还为大型语言模型在复杂推理任务中的应用提供了新的方向和思路。这一突破标志着字节跳动在人工智能领域的研究又迈上了一个新的台阶。