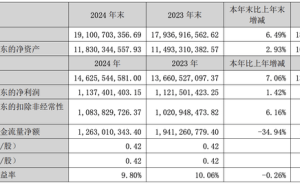
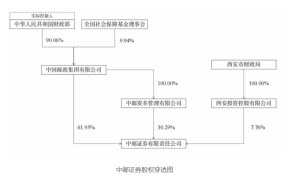
近日,AI领域内的焦点无疑被meta的新品发布所吸引,然而,这场原本备受期待的事件却意外地陷入了争议漩涡。

4月6日,meta终于揭晓了其酝酿已久的大模型新品——Llama 4系列,包括Llama 4 Scout(109B)、Llama 4 Maverick(400B)以及Llama 4 Behemoth。这一系列凭借“原生多模态MoE架构”、“性能超越DeepSeek V3”以及“1000万token上下文”等亮点,一经发布便引发了业界的广泛关注。一时间,“开源之光依旧能打”的声音不绝于耳,Llama 4似乎已稳坐巅峰。
然而,好景不长,随着开发者们对Llama 4的实际测评,一系列负面声音开始涌现。不少开发者发现,Llama 4的性能并不像官方宣传的那样出色,尤其在代码和逻辑推理方面,与GPT-4o、DeepSeek R1、Gemini 2.5 pro等竞品相比存在明显差距。更令人震惊的是,有自称meta内部员工的网友爆料称,Llama 4存在造假嫌疑,为了在激烈的竞争中抢占先机,meta在模型的后训练阶段中混入了多个benchmark测试集,以提升基准分数。据称,这一行为甚至导致了技术负责人的愤而离职。这一爆料迅速发酵,meta瞬间陷入了舆论的风口浪尖。
面对铺天盖地的质疑声,meta官方迅速做出了回应。他们坚决否认了造假和打榜的行为,并解释称,模型质量表现不一的原因在于,“我们在模型一准备好就立即发布了,所以预计在各个平台的公开实现需要几天时间才能完全稳定下来”。随后,meta首席AI科学家Yann LeCun也转发了澄清贴,力证meta的清白。然而,这番解释并未能平息众怒,反而引发了新的疑问:“如果模型还未稳定,meta为何急于发布?”
事实上,meta的焦虑早已显现。在Llama 4发布之前,meta上一次推出新品还是在去年7月,当时发布的Llama 3.1 405B模型曾一度风光无限。然而,随着今年年初DeepSeek凭借强大的多场景理解与内容生成能力成功出圈,AI领域的竞争格局发生了翻天覆地的变化。meta也感受到了前所未有的压力。有消息称,在DeepSeek崛起后,meta的研发进程被打乱,Llama 4在各项测试中均未能超越DeepSeek-V3。为了应对这一挑战,meta甚至在内部设置了四个作战室,天天研究DeepSeek,试图复现其模型能力。
然而,尽管meta付出了巨大的努力,Llama 4的性能表现却并未达到预期。即便是动用了20万的显卡集群,也未能挽回颓势。更糟糕的是,随着造假传闻的爆发,meta面临着巨大的信任危机。开发者们纷纷表示失望和不满,一些开发者甚至开始试图找出meta造假的证据。
如今,Llama系列模型昔日的光辉已然不再。对于meta而言,如何针对Llama 4存在的性能缺陷进行修复,重新夺回开发者的信任,已成为当务之急。这场原本备受期待的新品发布,最终却演变成了一场令人唏嘘的“闹剧”。meta的焦虑与急功近利,在这场风波中暴露无遗。面对DeepSeek这样的强劲对手,meta或许应该更加冷静和理智,以诚心之作来应对挑战,而不是急于求成、弄虚作假。