meta新推Llama 4系列AI模型,用户体验与官方宣传存在出入
近日,科技巨头meta震撼发布了其最新的AI模型系列——Llama 4,该系列一举推出了三款不同规格的模型:Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth。据meta官方宣称,这些模型在大模型竞技场中表现不俗,尤其Llama 4 Maverick更是在多项任务中排名领先。
然而,随着用户纷纷上手体验,Llama 4系列的实际表现却与官方宣传大相径庭。不少网友反馈称,尽管Llama 4 Maverick在开放模型排名中领先,但在专注于编程任务的Kscores基准测试中,其表现却不尽如人意,甚至不如GPT-4o、Gemini Flash等其他模型。
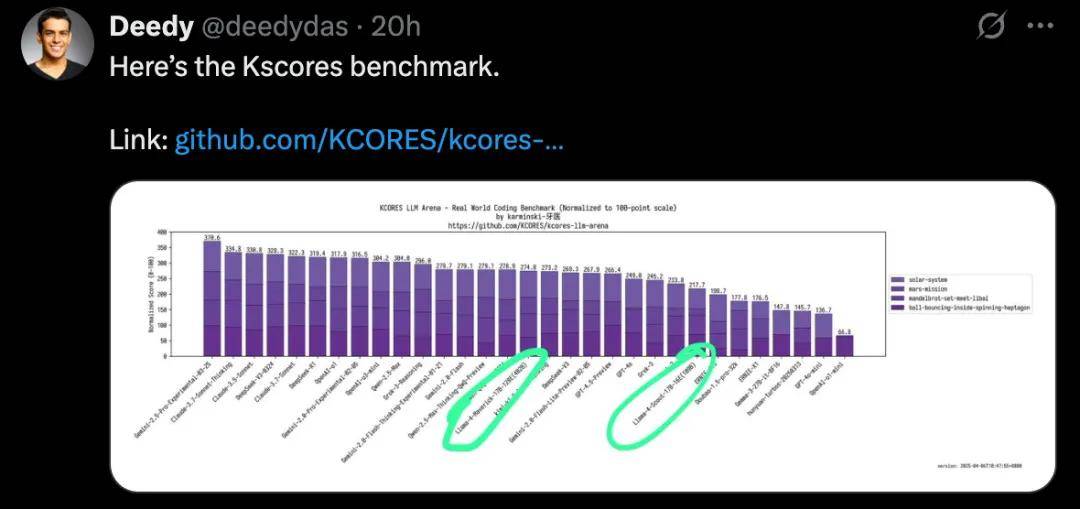
具体来说,在编程相关的测试中,如小球在旋转六边形中跳跃的任务,Llama 4的表现并不理想。网友们纷纷在评论区表示,无论是Scout还是Maverick,在实际编程中的使用体验都不尽如人意,即使有详细的提示也难以得到满意的结果。

还有网友在Novita AI平台上对Llama 4进行了测试,并得出结论称该模型在复杂问题上表现吃力,尽管其响应速度较快。这一反馈进一步引发了用户对Llama 4实际性能的质疑。
值得注意的是,Google Deepmind的工程师Susan Zhang也在社交媒体上对Llama 4的高分提出了质疑。她表示,不清楚Llama 4是如何在lmsys上获得如此高的分数的,并猜测是否meta为lmsys定制了一个专门的模型。

针对这一系列质疑,科技媒体TechCrunch报道称meta新AI模型的基准测试存在误导性。研究发现,公开可下载的Llama 4 Maverick与托管在LM Arena上的模型在行为上存在显著差异。LM Arena上的版本似乎使用了大量表情符号,并给出了冗长的回答。这一发现进一步加剧了用户对meta AI模型真实性能的担忧。