meta震撼发布Llama 4,开源大模型领域再掀波澜
科技巨头meta在近期推出了其最新的开源人工智能模型——Llama 4,这一举动在人工智能界引起了广泛关注。据悉,Llama 4系列包括Scout和Maverick两个版本,是meta迄今为止最尖端、多模态性最强的模型。
作为开源模型的先驱,meta在推动人工智能发展方面一直扮演着重要角色。早在ChatGPT问世仅七个多月后,meta便率先开源了Llama 2,并允许免费商用,这一举措标志着大模型发展的一个重要转折点。而此次Llama 4的发布,不仅是对新兴开源势力如DeepSeek的一次有力回应,更是开源模型技术进步的又一里程碑。
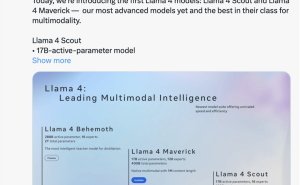
Llama 4系列模型引入了混合专家(MoE)架构,这一架构同样被DeepSeek系列模型所采用。相较于传统的稠密模型,MoE架构通过仅激活全部参数中的一小部分来处理单个token,从而显著提高了训练和推理的计算效率。Llama 4系列中的两款高效模型——Llama 4 Scout和Llama 4 Maverick,分别针对不同应用场景进行了优化。
Llama 4 Scout专注于文档摘要和大型代码库推理任务,专为高效信息提取与复杂逻辑推理而设计,拥有16位“专家”、1090亿参数和170亿激活参数量。而Llama 4 Maverick则以其卓越的多模态能力脱颖而出,支持视觉和语音输入,具备顶级的多语言支持和编程能力,配备128位“专家”、4000亿参数和170亿激活参数量。meta还预览了其迄今最强大、最智能的模型——Llama 4 Behemoth,拥有令人瞩目的2万亿总参数和2880亿激活参数量,堪称“新模型中的教师”。
Llama 4的另一大亮点是其突出的多模态能力。作为原生多模态模型,Llama 4采用了早期融合技术,能够利用海量的无标签文本、图片和视频数据共同预训练模型,实现文本和视觉token的无缝整合。通过训练两个模型以赋予它们广泛的视觉理解能力,Llama 4支持多图像输入与文本提示的无缝交互,用于视觉推理和理解任务。
在长文本处理能力方面,Llama 4同样取得了显著突破。Llama 4 Scout模型支持高达1000万token的上下文窗口,刷新了开源模型的纪录,使得Llama 4在处理长文档、复杂对话和多轮推理任务时表现出色。这一优势为Llama 4在多种应用场景中提供了强大的竞争力。
随着Llama 4的发布,大模型领域的竞争愈发激烈。作为开源模型社区的佼佼者,meta自2022年推出Llama系列模型以来,一直引领着开源模型的发展潮流。面对ChatGPT等领先闭源模型的挑战,meta于2023年率先开源Llama 2,并允许免费商用,这一举措极大地激发了开发者社区的创新活力,形成了充满活力的生态系统。
然而,开源领域的竞争并非一帆风顺。随着DeepSeek等新兴势力的崛起,meta在开源模型社区的领先地位受到了前所未有的挑战。阿里巴巴通义千问系列开源大模型也展现出强劲实力,多次斩获佳绩。在全球最大的AI开源社区Hugging Face的大模型榜单上,阿里通义千问近期开源的端到端全模态大模型Qwen2.5-Omni更是登上了总榜榜首。
在Llama 4发布之际,其他科技巨头也纷纷透露了各自的模型发布计划。OpenAI首席执行官山姆·奥特曼表示,公司可能将在几周后发布最新的推理模型o3和最新的基座模型o4-mini,并在几个月后推出GPT-5。而DeepSeek则与清华大学研究团队联合发布了重磅论文,提出了提升大语言模型推理能力的新方法论,为下一代推理模型R2的发布奠定了重要技术基础。