在近期举办的2025中关村论坛“未来人工智能先锋论坛”上,创新工场董事长及零一万物CEO李开复发表了一场引人深思的演讲,主题为《全球视角下的生成式AI展望》。他深入剖析了当前全球大模型训练语料存在的语言偏见问题,并对此表达了深切担忧。
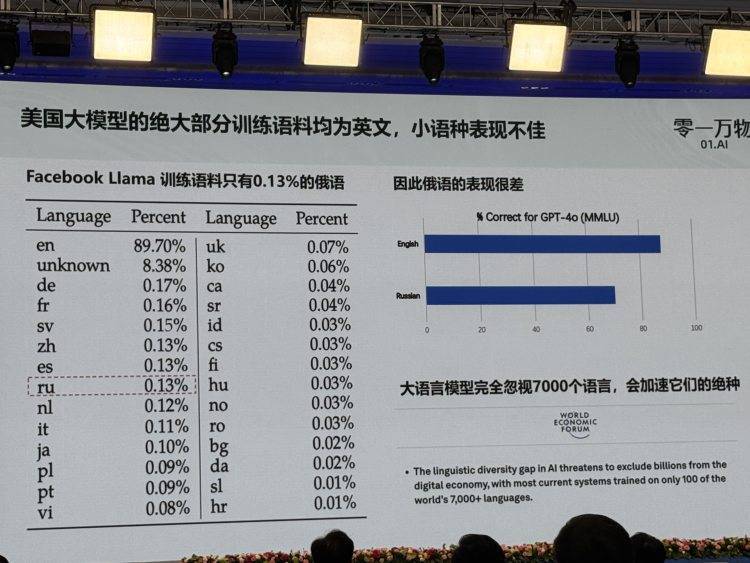
李开复指出,当前美国的大多数大型语言模型主要以英文语料进行训练,这导致小语种的表现不尽如人意。他强调,全球有超过7000种语言被这些模型所忽视,这可能会加速这些语言的消亡。他以Facebook LIama为例,指出其训练语料中俄语仅占0.13%,导致俄语使用效果不佳。他进一步提到,东南亚、中东、中亚及非洲等地区,由于语言多样性,使用大模型更加困难。
李开复还提及了康奈尔大学的一项研究,该研究显示美国大模型的价值观与欧美价值观高度一致,与其他地区存在偏差。他呼吁各国应有机会开发自己的模型,使用本土语言和价值观推动大模型的发展。他透露,零一万物正在积极推出小语种模型,并寻求与相关国家地区的合作,以促进大模型的全球公平发展。
在演讲中,李开复还对DeepSeek引发的变革进行了深入解读。他认为,DeepSeek通过开源推理模型的思考训练过程,显著缩小了中美在这一领域的差距。他指出,开源模型的能力正在迅速追赶闭源模型,这将进一步推动SOTA模型的商品化。同时,DeepSeek的高效工程效率与OpenAI的巨额融资策略形成了鲜明对比。李开复强调,DeepSeek Moment将极大地加速大模型在中国的全面落地。
然而,李开复也指出,尽管DeepSeek模型表现出色,但企业在落地过程中仍需解决安全部署、应用实践和行业定制等三大挑战。他建议,企业应快速实现私有化安全部署,针对行业场景推进应用,并在应用过程中让大模型的自我进化能力得到进一步增强。
最后,李开复对AI技术的未来发展表达了乐观态度。他认为,2025年将是AI应用大规模落地的元年。他指出,过去两年大模型能力不断提升,回答问题能力已远超人类;新技术持续突破,数字化AI与真实物理世界的融合将进一步加深。大模型的推理成本正迅速下降,AI 2.0的普惠点将加速产业渗透。相比云计算,AI 2.0应用层的爆发周期将显著缩短至两年内。