近期,全球AI产业格局正经历一场前所未有的变革,其导火索是中国两家新兴AI企业——DeepSeek与Manus在短短三个月内所掀起的创新狂潮。
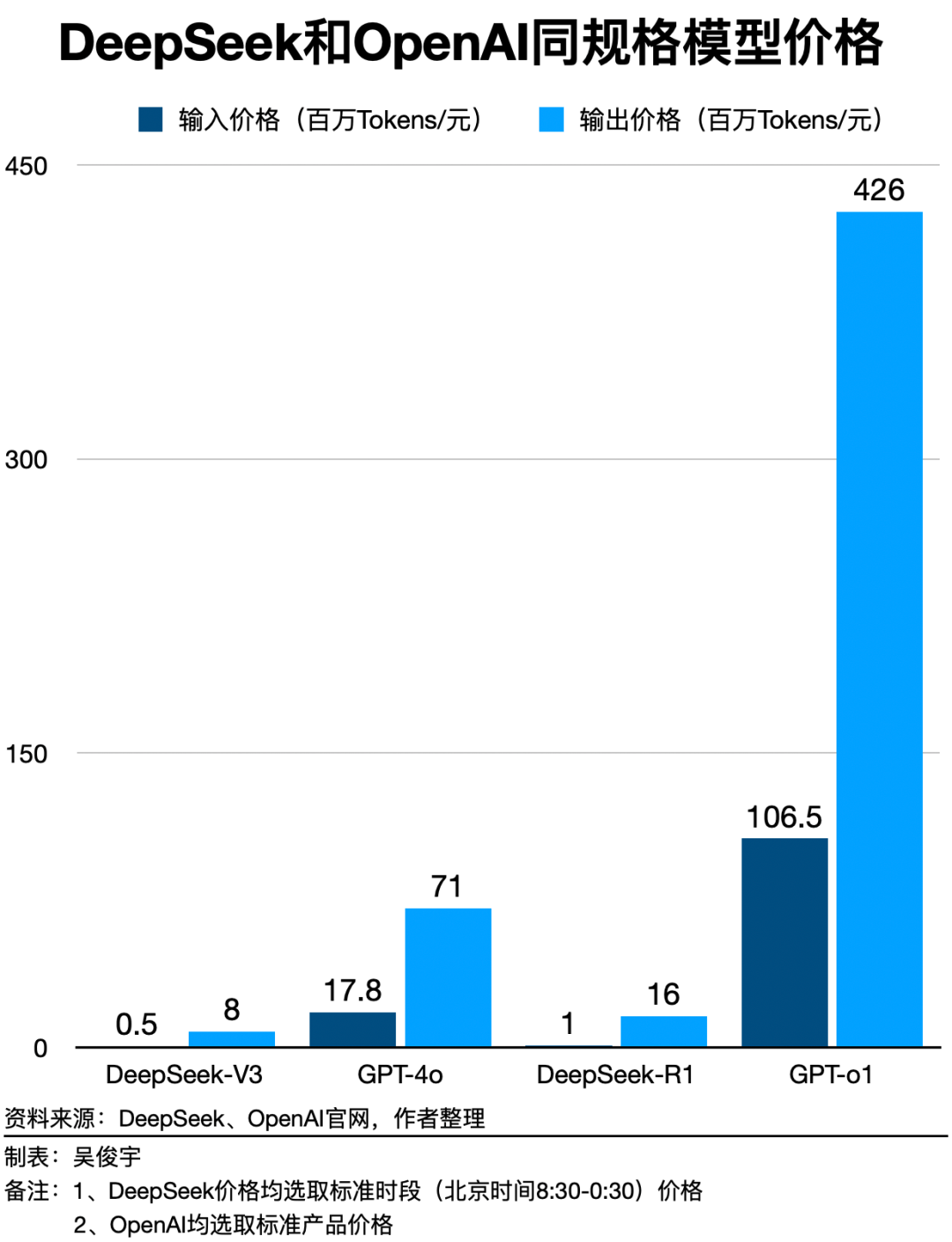
DeepSeek凭借其声称的“以2048张英伟达H800芯片和558万美元训练成本”打造的DeepSeek-V3模型,成功吸引了业界的广泛关注。该模型在性能上已逼近美国OpenAI公司的GPT-4,这一成就无疑为全球AI竞赛注入了新的活力。

与此同时,Manus公司则通过Muti-Agent(多代理)策略,开创性地推出了一款被认为是2025年AI应用发展方向的原生AI应用。该应用能够独立思考、规划并执行复杂任务,展示了AI技术在实际应用领域的巨大潜力。
尽管DeepSeek与Manus的成就备受瞩目,但两者也面临着不少争议。DeepSeek所披露的算力规模和训练成本受到市场质疑,而Manus则被部分人士认为缺乏真正的核心竞争力。
然而,无论争议如何,这两家公司无疑已成为大模型浪潮中的里程碑。它们所引发的变革意味着,拥有云业务的科技巨头如亚马逊、微软、谷歌和阿里巴巴等,其未来三年的战略规划将面临重大调整。
一方面,过去三年大模型的竞争焦点主要集中在训练上,但近期正逐渐转向推理。随着“规模定律”的放缓,成倍的算力提升只能带来有限的模型性能增长。然而,得益于芯片、模型和算法的不断优化,推理算力的成本正以惊人的速度下降。
另一方面,AI应用的快速发展也受益于推理算力的下降。过去,高昂的推理算力成本是AI应用落地的主要障碍。但如今,随着成本的降低,老应用如钉钉、飞书、WPS和美图秀秀等正加速融入新的AI功能,而像Manus这样的原生AI应用也迅速崛起。
在这场变革中,全球四大云厂商——亚马逊、微软、谷歌和阿里巴巴,正积极应对挑战,寻求新的发展机遇。
为了抓住DeepSeek带来的早期市场红利,这些云厂商迅速接入DeepSeek模型。由于DeepSeek-V3/R1是开源的,任何人都可以下载、部署和使用,因此云厂商在接入过程中并无太大技术障碍。客户在使用时会消耗算力和数据,从而带动其他基础云产品的销售。
然而,面对第三方模型的兴起,一些云厂商的心态复杂。它们既希望销售自家的旗舰模型,又担心第三方模型会抢占市场份额。因此,在接入DeepSeek时,它们表现得犹豫、被动甚至摇摆不定。
相比之下,亚马逊的态度则显得坚决而迅速。它不仅率先接入DeepSeek,还为客户提供了一整套使用DeepSeek的工具链。通过Amazon Bedrock平台,客户可以以全托管、无服务器的方式使用DeepSeek-R1,这种体验如同使用一方官方推荐的产品。

面对DeepSeek的技术创新,各大云厂商也纷纷加快了自研模型的步伐。落后者迅速追赶,领先者则观望后立刻反制。微软和OpenAI推出了性能更强的o3-mini和GPT-4.5,而阿里巴巴则发布了对标DeepSeek-V3的Qwen2.5-Max。
在这场竞赛中,亚马逊更注重模型的实用性和业务表现。它强调模型的响应速度、吞吐效率和安全可靠,而非单纯的评测跑分。通过“吃自己的狗粮”(使用自家生产的产品)的策略,亚马逊让自家模型经过业务检验,不断提升性能。
随着AI应用的爆发和算力需求的增长,加大算力投入已成为大势所趋。尽管DeepSeek的崛起一度引发市场担忧,认为这会减少算力需求,但乐观预期很快占据主流。中美四大科技公司均公布了2025年资本支出计划,加码算力投入。
在这场算力竞赛中,亚马逊以其自研芯片的优势脱颖而出。通过大规模采购基于Arm架构的Graviton系列芯片,亚马逊成功降低了算力成本,提高了性价比。这一策略不仅增强了亚马逊在AI竞赛中的竞争力,也为其他科技公司提供了有益的借鉴。