Hugging Face的Open R1项目近期迎来了重大突破,其奥林匹克编程模型OlympicCoder在代码推理领域大放异彩,力压Claude 3.7 Sonnet等一众顶尖模型。
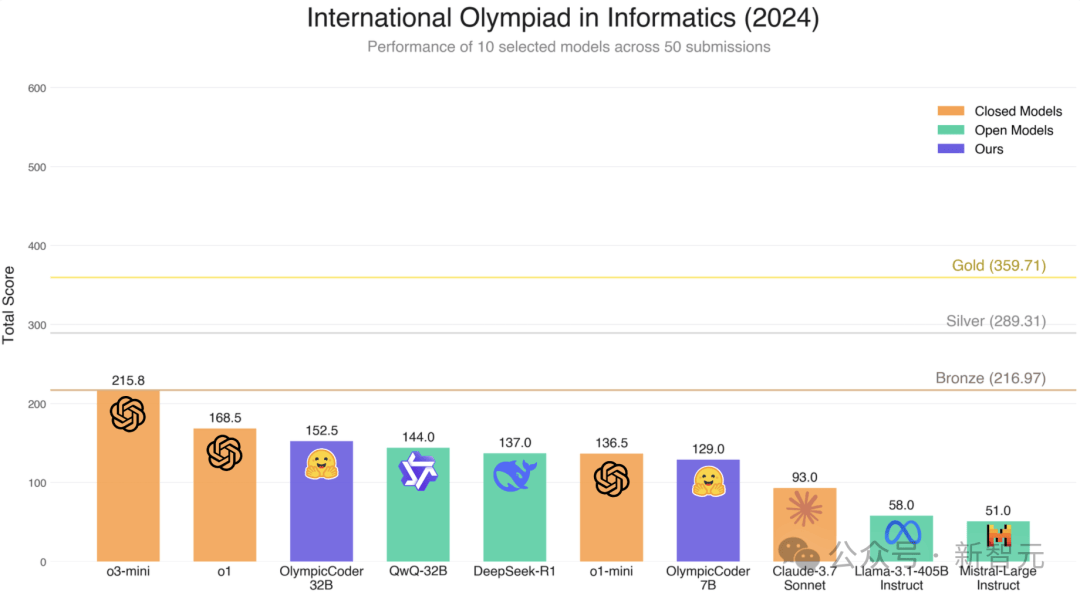
这一成就的背后,是Open R1项目团队的不懈努力与创新。他们精心打造了CodeForces-CoTs数据集,该数据集包含了近10万个高质量样本,专门用于训练C++和Python代码生成。这些样本提炼自DeepSeek-R1,为奥林匹克编程模型的训练提供了坚实的基础。
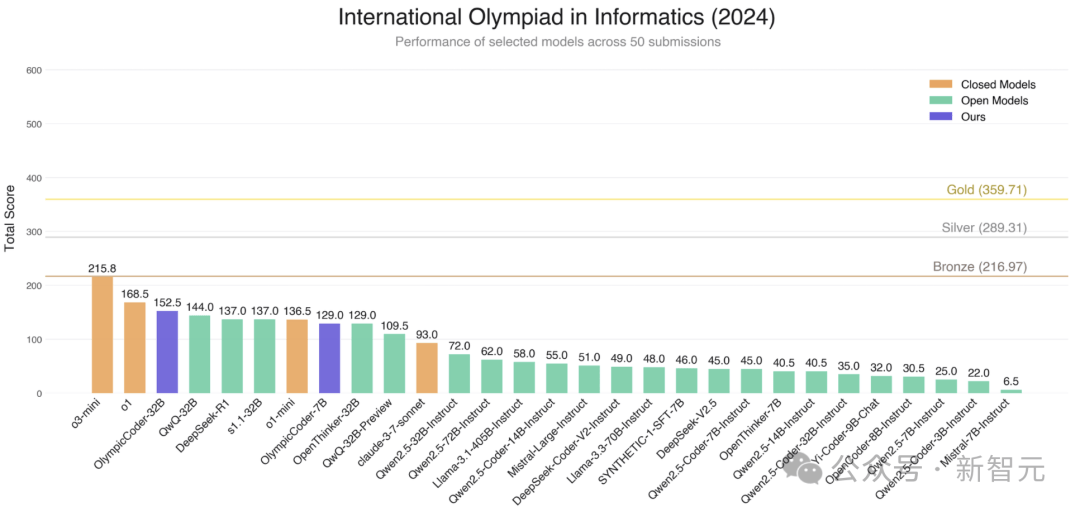
为了验证模型的性能,团队选择了国际信息学奥林匹克竞赛(IOI)作为基准测试。IOI作为全球顶尖的编程竞赛,其问题设计独特且极具挑战性。团队整理了2020-2024年的IOI问题,并将它们拆分为子任务,以便有针对性地训练和评估模型。结果显示,OlympicCoder模型在IOI基准测试上表现出色,特别是在50次提交限制下,OlympicCoder-32B超越了多个领先模型。
在创建OlympicCoder模型的过程中,团队遇到了不少挑战。其中,代码可验证性危机是一个棘手的问题。尽管DeepMind和其他竞赛数据集都包含测试用例,但这些通常只是竞赛网站上全套测试用例的一小部分。为了解决这个问题,团队采用了IOI的完整测试集,并遵循宽松的许可发布,使其成为测试代码推理能力的理想数据集。
团队还优化了提交策略,以模拟真实竞赛场景。他们采用了类似OpenAI的策略,让模型最大化得分,像真正的选手一样参加比赛。这种策略在IOI基准测试上取得了显著效果,进一步提升了OlympicCoder模型的性能。
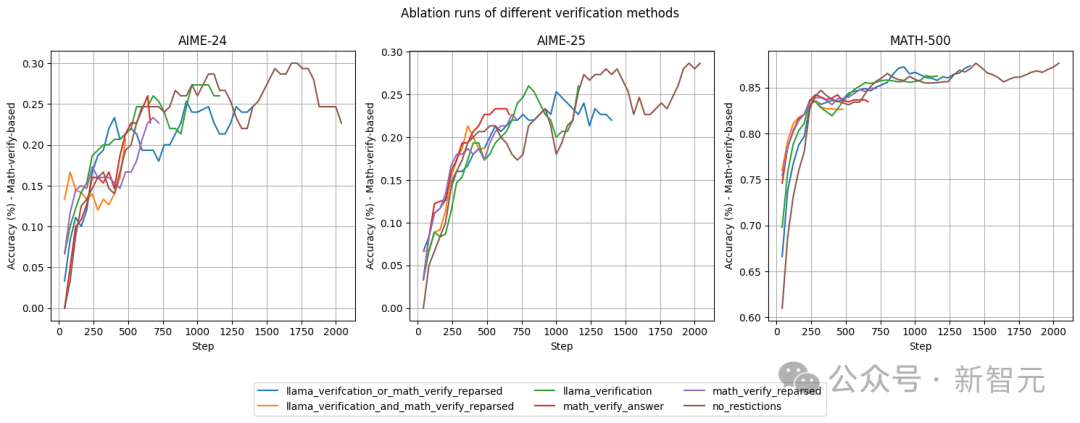
在训练过程中,团队也积累了丰富的经验教训。他们发现,样本打包会损害推理性能,因为很多推理轨迹较长,答案被截断的可能性高。较大的学习率有助于获得最佳表现,而在训练时直接从问题描述采样,也能让性能有持续提升。这些发现为后续的模型优化提供了重要指导。
团队还巧妙地将8位优化器与FSDP结合使用,成功将上下文扩展到22,528个token,从而支持了更大模型的训练。这一创新不仅解决了内存问题,还进一步提升了模型的性能。
除了奥林匹克编程模型外,Open R1项目还在不断丰富和完善其数据集。最近,研究团队对OpenR1-Math-Raw数据集进行了更新,添加了新的元数据以支持更明智的过滤和验证决策。这一举措将有助于提高数据集的准确性和可靠性,为后续的模型训练提供更有力的支持。
随着Open R1项目的不断发展和壮大,其在代码推理领域的领先地位也日益巩固。未来,我们有理由相信,Open R1项目将继续引领代码推理技术的发展潮流,为人工智能领域注入更多创新和活力。