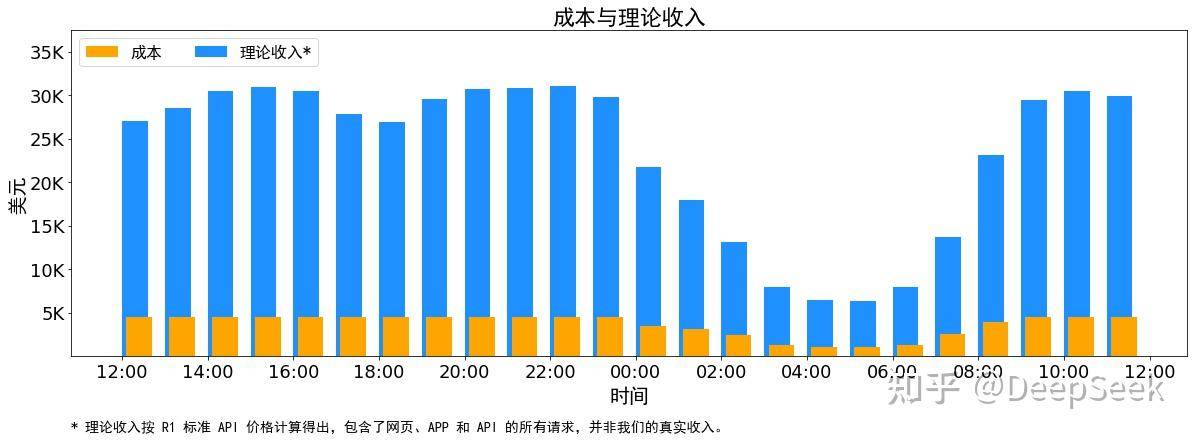
在AI界万众瞩目的DeepSeek“开源周”闭幕之际,该公司抛出了一个震撼业界的消息——首次公开其成本利润率的关键数据。DeepSeek通过官方社交媒体账号宣布,在假定GPU租赁成本为每小时2美元的情况下,其日常总成本高达87,072美元。然而,若所有tokens均按照DeepSeek R1的定价出售,理论上一天的总收入可达562,027美元,成本利润率惊人地达到了545%。
尽管这一数据描绘了一幅理想化的盈利图景,但不可否认的是,DeepSeek的开源周活动已经激发了整个行业的热情。通过提供一系列开源工具,DeepSeek不仅极大地降低了全球AI开发者进行模型开发和训练的成本,还为大模型开源与闭源的长期争论带来了初步的答案。
近期,包括百度、字节跳动、昆仑万维在内的多家科技巨头纷纷宣布推出或深化其开源模型战略。百度,这个曾经的坚定“闭源派”,也在今年2月宣布将开源其下一代文心大模型。这一转变标志着开源大模型的浪潮已势不可挡。
“无论是主动还是被动,开源大模型的趋势已经被带动起来了。”开源大模型社区OpenCSG的联合创始人兼CTO王伟感慨道。DeepSeek的开源行动正在重塑AI大模型的市场格局,高速迭代的态势使得过时模型迅速被淘汰,而短期的算法技术优势或商业模式已难以构建长期的竞争壁垒。
DeepSeek的开源策略不仅为开发者带来了福音,也让一些大模型公司感受到了压力,不得不“跟风”开源。然而,开源之后,如何找到盈利模式成为了这些公司面临的新挑战。DeepSeek能够测算自己的理论利润率,但其他厂商是否也能找到适合自己的盈利路径,仍是一个未知数。
DeepSeek的开源行动不仅限于模型和论文,更向更底层的技术领域进发。王伟指出,DeepSeek开源的技术能够显著提高推理效率,减少所需GPU数量,甚至有助于节能减排。例如,DeepSeek开源的EP(Expert Parallelism,专家并行)技术,过去只有少数头部公司能够实现,而现在,随着DeepSeek的开源,更多企业有望享受到这一加速技术带来的好处。

LangGPT社区的创始人云中江树认为,DeepSeek的开放程度几乎拉平了大模型应用的门槛。DeepSeek不仅开放了模型的权重,还几乎没有任何限制地开放了训练代码和底层部署代码,这使得其他企业和开发者能够更高效地部署和使用大模型。
DeepSeek的开源行动不仅促进了技术创新,还扭转了大模型开闭源的战局。过去一段时间,海外大模型开源势头有所减弱,而DeepSeek等中国模型则成为了开源的重要力量。百度等科技巨头也纷纷转向开源,这一转变背后,或许隐藏着更深层的生态战位考量。
随着DeepSeek的风暴席卷而来,其他大模型厂商也面临着选择:是跟风开源,还是坚持闭源?百度创始人李彦宏在财报电话会议上解释了百度开源决策的背后原因,希望通过开源促进模型的采用,并展示文心系列大模型的真正价值。这一决策背后,或许也蕴含着百度对AI生态战位的深刻洞察。
然而,开源之后如何商业化,仍然是许多企业面临的难题。DeepSeek的商业化路径也并不清晰,但其开源策略已经对其他大模型厂商构成了压力。云中江树指出,即使是闭源的大模型,其商业化也并不理想。当前大模型的智能化水平尚未达到真正商业化落地的要求,这或许是所有大模型厂商都需要面对的现实。