近期,一份关于DeepSeek模型在2025年的优势分析报告引起了业界的广泛关注。该报告深入探讨了DeepSeek模型在算力与成本方面的突出表现,并分析了当前国内AI发展所面临的机遇与挑战。
随着技术的不断进步,算力已经从传统的信息计算力发展成为涵盖信息计算力、数据存储力以及网络运载力的现代综合算力。尤其是在人工智能大模型时代,对算力的需求急剧增加。例如,万亿级别的模型需要处理的数据量超过1.5万亿亿次,计算次数更是高达1.5亿亿亿次,这使得高昂的算力成本成为制约AI发展的关键因素之一。
在对比国内外AI发展模式时,报告指出,国际企业如OpenAI通过资本市场融资,采购最新GPU来训练大模型并提供服务。而国内AI企业在发展模式上与国际企业相似,但由于受到美国的技术封锁,如高端AI芯片出口禁令、AI加速器互联带宽限制以及特定芯片代工和HBM芯片供应禁止等,导致国内AI优质算力与国外相比存在一定的差距。
然而,DeepSeek模型却在这一背景下脱颖而出。DeepSeek V3在多个测评中均表现出色,且其训练成本相对较低。这得益于DeepSeek模型在技术创新上的突破,如DeepSeekMoE技术,该技术采用1共享专家+256路由专家的架构,使得每个Token仅需通过360亿参数,从而大幅减少了计算量。MLA技术通过低秩压缩KV,使得KV Cache的使用降低了93.3%,这不仅提升了推理性能,还有效降低了成本。DeepSeek还自研了轻量级框架,结合FP8训练、DualPipe等技术,进一步提升了算力密度和系统性能。DeepSeek还通过PTX优化在一定程度上绕开了CUDA的限制,虽然尚未完全摆脱依赖,但对国产硬件设计具有一定的借鉴意义。


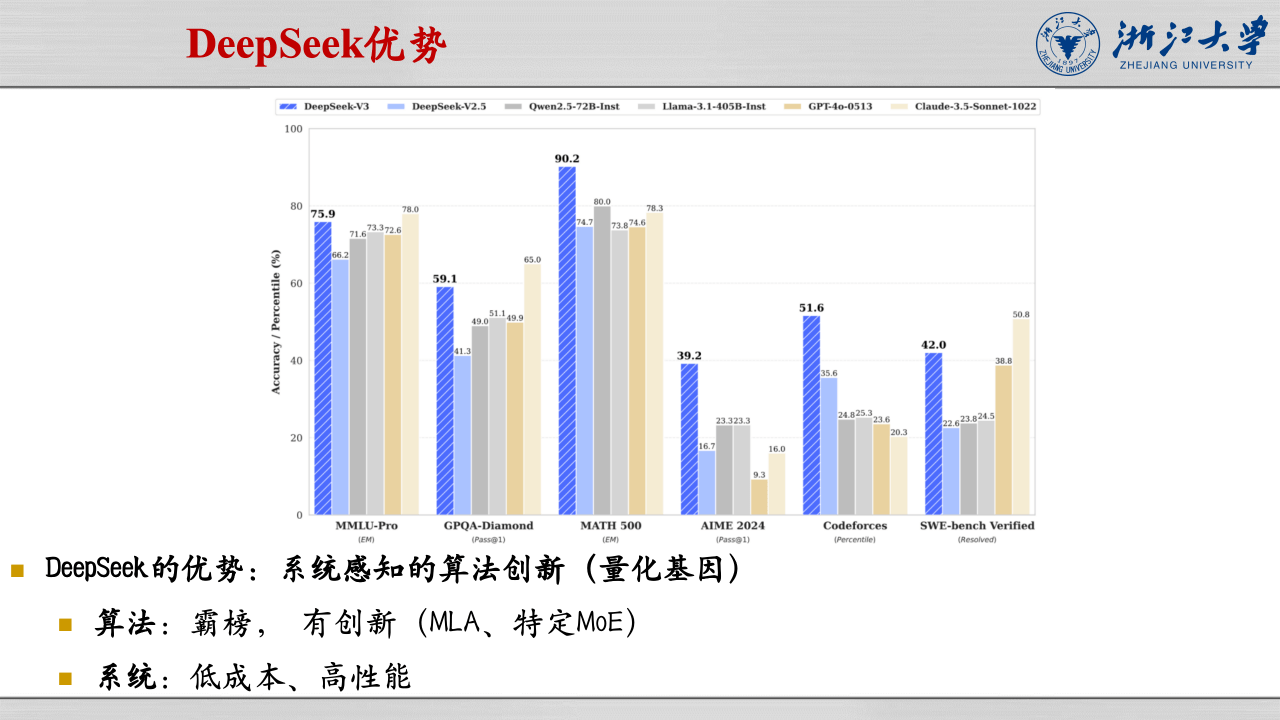


报告还指出,以DeepSeek为代表的国内大模型在成本上具有显著优势,但由于受到算力限制,短期内全面超越国外先进模型仍存在较大难度。因此,未来国内AI产业的发展需要中芯国际等企业突破工艺瓶颈,华为等企业提供高算力支持,共同提升国内AI产业的国际竞争力。