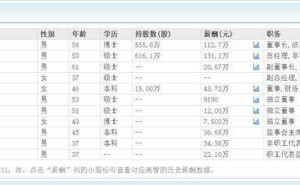
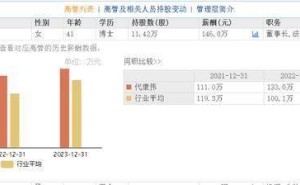
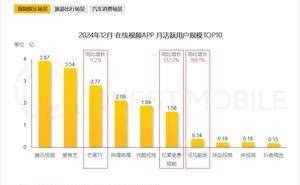
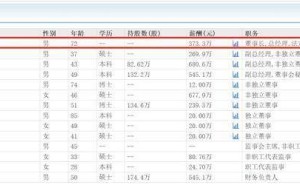
近日,杭州的Deepseek公司犹如一颗重磅炸弹,在春节前夕震撼了整个科技投资界,引发了华尔街的轩然大波。
Deepseek推出的开源AI模型,在多个关键指标上超越了OpenAI的同类产品,而其研发成本仅为600万美元,相比之下,OpenAI则花费了数十亿美元。这一消息迅速在业界传开,引发了对AI研发模式的深刻反思。

Deepseek的崛起,让华尔街的投资者们开始质疑,以往那些斥巨资购买显卡以构建大型AI模型的做法是否明智。是否算力堆砌的背后,隐藏着不为人知的泡沫?这一担忧迅速蔓延,导致美股科技巨头的股价集体跳水,其中英伟达一夜之间暴跌17%,市值蒸发超过4万亿元。博通、AMD、微软、台积电等科技巨头也未能幸免,市场普遍认为,AI领域的估值逻辑可能正在发生深刻变化。
Deepseek的成功,让人们看到了低成本、高效率AI研发模式的可能性。然而,就在业界准备追随Deepseek的脚步时,马斯克旗下的xAI公司却给出了截然不同的答案。
xAI公司发布了名为Grok 3的新大模型,在LMSYS盲测和AIME竞赛中均表现出色,马斯克自豪地宣称其为全球最聪明的AI。Grok 3的最大亮点在于其庞大的算力支持,堆砌了20万张H100显卡,用实际行动诠释了“大力出奇迹”的真谛。

Grok 3的成功,不仅证明了马斯克在AI领域的深厚底蕴,也再次验证了规模定律的有效性。在AI领域,算力仍然是决定模型能力的关键因素之一。只要有足够的显卡和算力支持,大模型的能力就能得到显著提升。因此,尽管Deepseek的低成本模式令人眼前一亮,但持续投入芯片、数据中心和云基础设施仍然是硬道理。
值得注意的是,Grok 3的成功并未让Deepseek的光芒黯淡。相反,它激发了业界对于AI研发模式的更多思考。在未来的AI领域,低成本与高效率并重,或许将成为新的发展趋势。然而,无论采用何种模式,算力都将是不可或缺的基石。