在AI领域的一场静悄悄的技术革命中,DeepSeek公司凭借其创新的原生稀疏注意力(Native Sparse Attention, NSA)机制,正逐步成为行业的焦点。就在马斯克高调推出新产品,而Sam Altman在开源策略上犹豫不决之时,DeepSeek悄然发布了一项可能颠覆游戏规则的新技术。
近日,DeepSeek的首席执行官在公开场合透露,由梁文锋亲自参与的研究论文成果——NSA机制,是团队在稀疏注意力领域的突破性创新。这一机制结合了算法上的创新和硬件上的优化,旨在解决长上下文建模中的计算瓶颈问题。
根据DeepSeek的研究论文,NSA机制不仅将大语言模型处理64k长文本的速度提升了最高11.6倍,而且在通用基准测试中,其性能甚至超过了传统的全注意力模型。在全球AI竞赛日益转向“硬核创新”的背景下,这家低调的中国公司以其独特的技术路径,展示了破局的新思路。
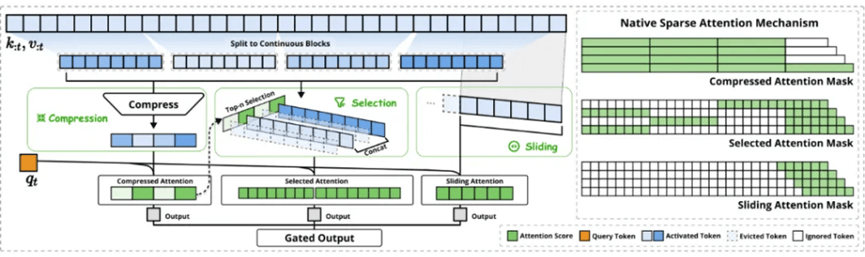
值得注意的是,尽管NSA机制尚未应用于DeepSeek V3的训练中,但已有迹象表明,一旦将其整合到模型训练中,基座模型的能力有望实现显著提升。论文明确指出,使用NSA预训练的模型已经超越了全注意力模型。
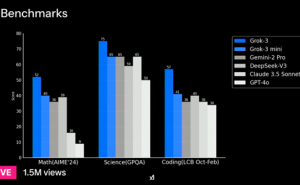
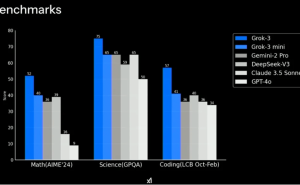
与此同时,xAI则选择了截然不同的道路,即追求工程规模的极致。马斯克发布的Grok3使用了20万块GPU集群,而未来的Grok4更是计划使用百万块GPU、1.2GW的集群。这种“财大气粗”的做法,无疑体现了北美在AI领域一贯的“大力出奇迹”风格。
然而,与xAI的“堆算力”策略相比,DeepSeek的NSA机制则显得更为巧妙和高效。NSA机制通过动态分层稀疏策略、算术强度平衡的设计以及端到端可训练的特性,实现了高效的长文本建模。其核心组件包括压缩注意力、选择注意力和滑动窗口注意力三个并行的注意力分支,通过门控机制进行聚合,从而最大化效率。
实验结果显示,NSA技术在多个方面都展现出了卓越表现。在通用基准测试、长文本任务和指令推理方面,使用NSA预训练的模型性能不仅没有下降,反而超越了全注意力模型。更重要的是,在处理64k长度的序列时,NSA在解码、前向传播和反向传播等各个阶段都实现了显著的速度提升,最高可达11.6倍。
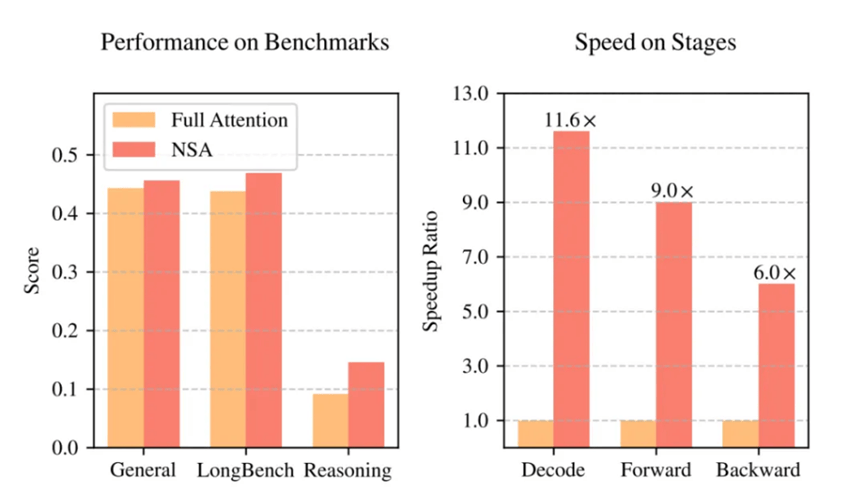
AI寒武纪的分析指出,DeepSeek的NSA技术为长文本建模带来了新的突破。它不仅在性能上超越了传统的全注意力模型,更在效率方面实现了显著提升,尤其是在长序列场景下。NSA的硬件友好设计和训推一体化特性,使其在实际应用中更具优势,有望加速下一代大语言模型在长文本处理领域的应用落地。
DeepSeek在模型研发阶段就已经开始考虑未来适配更多类型计算卡的问题。NSA机制降低了浮点算力和内存占用门槛的特性,或许暗示了DeepSeek正在为更广泛、更普遍的开源做准备。与xAI通过超大集群在短时间内实现性能反超但投入产出比并不理想的情况相比,DeepSeek的NSA机制无疑提供了一种更为高效和可持续的发展路径。