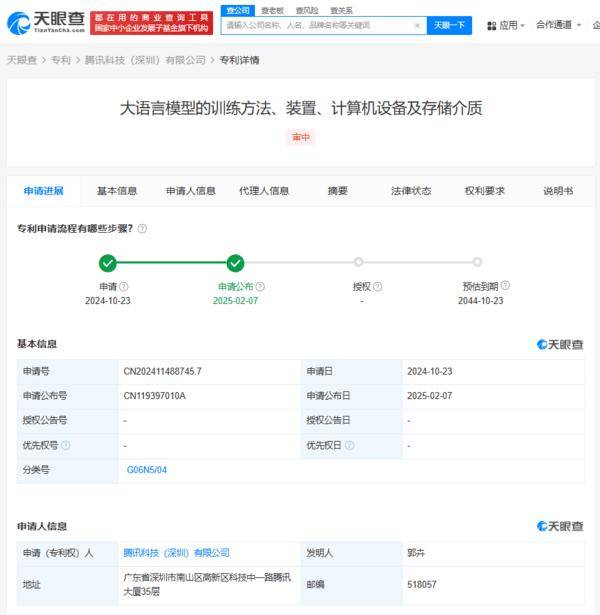
腾讯科技(深圳)有限公司近日公布了一项名为“大语言模型的训练方法、装置、计算机设备及存储介质”的专利,该专利于2月7日正式发布。这项新技术通过引入多重摘要文本的对比学习机制,在大语言模型训练中取得了显著成效,有效提升了模型的泛化能力和生成准确性,为AI语言处理领域带来了新的突破。

据专利摘要介绍,腾讯的新方法创造性地采用了“第一摘要文本”与“第二摘要文本”的对比学习模式。这两种摘要文本在信息量上存在差异,且第一摘要文本包含了正确与错误语句的混合。模型通过对比这两种摘要,学会了如何区分正确与错误的表达方式,同时有效减少了因单一数据源导致的过拟合问题。这一设计不仅拓宽了模型的学习维度,还通过动态调整机制,进一步提升了生成结果的可靠性。
值得注意的是,腾讯此次的专利创新与近年来对比学习在文本摘要领域的应用趋势不谋而合。对比学习通过构造正负样本,调整模型表示空间,已在提升摘要质量、缓解暴露偏差等方面取得了显著成效。而腾讯将对比学习框架融入大语言模型训练,无疑进一步拓展了这一技术的应用范围。

媒体分析指出,腾讯的这项专利通过多样化的摘要文本和对比机制,为模型提供了一个更加贴近实际应用场景的学习环境。这对于智能客服、内容生成等需要高精度输出的领域来说,具有直接的现实意义。该技术还有望加速大模型的落地进程。例如,在短文本对话场景中,腾讯此前已推出了基于混合注意力机制的对话模型专利。若结合此次的新训练方法,将有望进一步提升对话回复的相关性和丰富性。
腾讯近年来在大语言模型领域的动作频频,从2023年的微调方法专利到此次的训练框架创新,无不显示出其在该领域全链条技术布局的雄心壮志。这一系列的创新成果,不仅为腾讯在AI语言处理领域树立了领先地位,也为整个行业的发展带来了新的动力。