春节期间,全球AI领域迎来了一位新晋明星——中国的大模型DeepSeek,其在全球范围内引发了广泛讨论与关注。
DeepSeek R1的发布,直接对标了OpenAI去年推出的o1系列模型,迅速成为全球AI圈的焦点。数据显示,1月27日,DeepSeek在中国区和美国区的苹果App Store免费榜上同时登顶,单周下载量高达约240万次。这一火爆程度,让OpenAI CEO奥特曼都感叹:“这是个令人印象深刻的模型。”英伟达更是将其誉为最先进的大语言模型。

与OpenAI在模型上的闭源及o1模型的付费使用限制不同,DeepSeek R1不仅开源,还免费供全球用户无限调用。这一举措,无疑在全球范围内引发了AI从业者的跟随,同时也引发了一些恐慌和攻击。
DeepSeek的出现,打破了AI大模型领域“拼算力”的共识。据悉,DeepSeek用不到OpenAI十分之一的资源,就打造出了性能对标OpenAI o1的DeepSeek R1。这一消息,让资本市场瞬间产生了微妙的变化。截至1月27日美股收盘,美股科技股大跌,费城半导体指数下跌9.2%,英伟达股价更是下跌近17%。
DeepSeek的火爆,也让它迅速成为了全球AI领域的中心话题。不仅OpenAI感受到了压力,两周内接连发布三个大模型:Operator、Deep Research和推理模型o3-mini,就连meta内部员工也爆料称,meta的生成式人工智能部门陷入了恐慌。
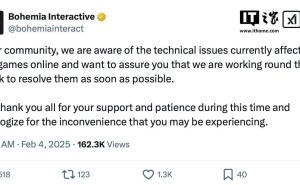
然而,DeepSeek的崛起之路并非一帆风顺。1月28日凌晨,DeepSeek官网连续发布两条公告,称DeepSeek线上服务受到了大规模恶意攻击。尽管如此,DeepSeek依然以其强大的实力和创新能力,站在了AI领域的风口浪尖。

DeepSeek之所以能够在短时间内取得如此大的成功,与其技术创新和低成本思路密不可分。DeepSeek摒弃了传统的监督微调路径,转而通过强化学习来优化推理路径。这一创新性的训练方法,不仅提高了模型的性能,还大大降低了训练成本。
以DeepSeek R1为例,其性能与GPT o1相当,但预训练成本仅为557.6万美元,仅为GPT-4o的十分之一。同时,DeepSeek API服务的定价也远低于OpenAI。这一低成本、高性能的模型,无疑给AI行业带来了新的启发和变革。
DeepSeek的成功,也引发了全球范围内对开源和闭源路线的讨论。此前,OpenAI推出的ChatGPT和Anthropic推出的Claude均采用闭源策略,并凭借头部影响力将闭源路线推到领先位置。然而,DeepSeek的成功无疑给支持开源路线的人带来了信心。meta首席人工智能科学家Yann LeCun更是表示:“DeepSeek的成功代表了开源人工智能模型的胜利。”

DeepSeek的崛起,不仅打破了AI大模型领域的旧有格局,还引发了全球范围内的蝴蝶效应。OpenAI等AI巨头纷纷调整策略,跟随DeepSeek的步伐。同时,DeepSeek的成功也给全球AI行业带来了新的启示和思考。
如今,DeepSeek已经成为全球AI领域的新星,其低成本、高性能的模型和创新性的训练方法,正在深刻地变革着整个AI产业链。未来,DeepSeek将继续引领AI领域的发展潮流,为全球AI行业注入新的活力和动力。