国产大模型Qwen2.5-Max在Chatbot Arena榜单大放异彩
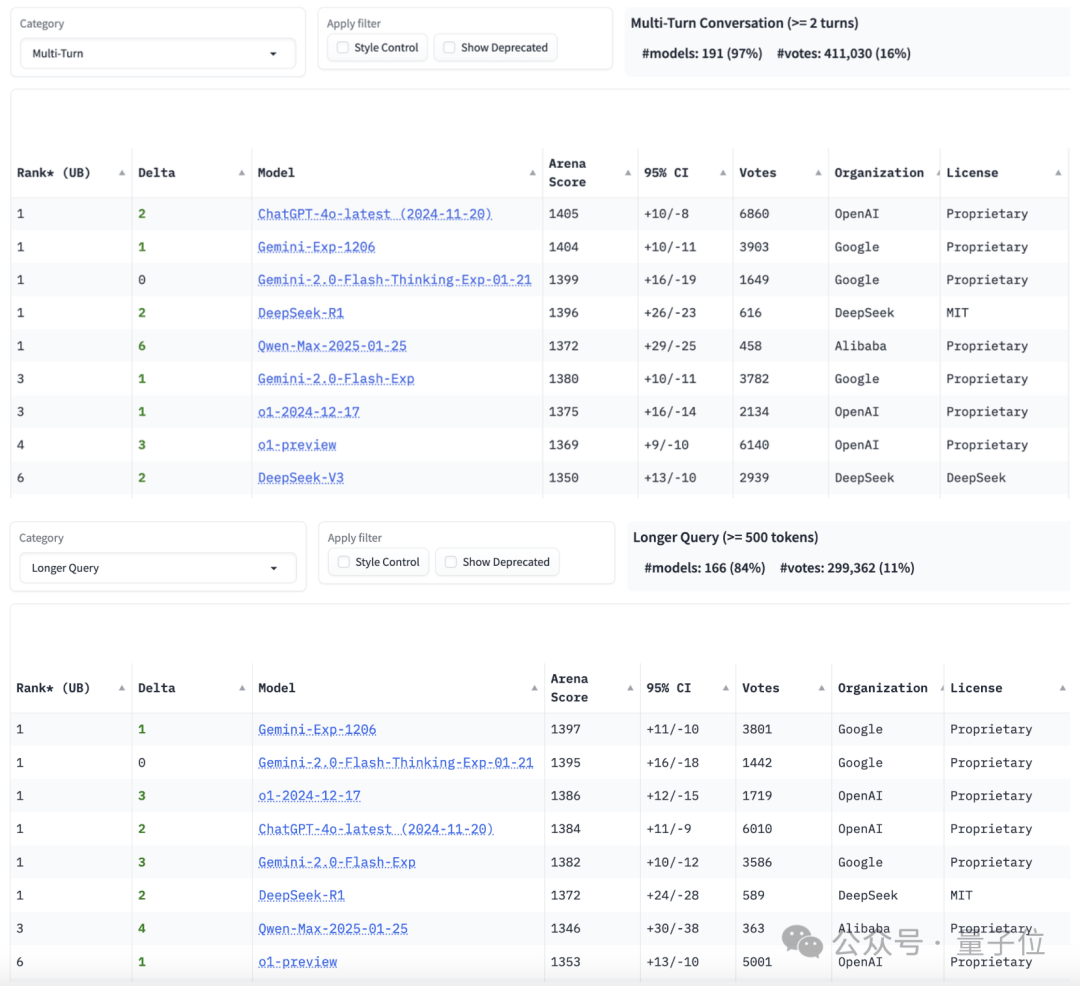
近日,在备受瞩目的大模型竞技场Chatbot Arena上,一款来自中国的AI模型Qwen2.5-Max凭借其卓越表现,成功跻身总榜第七名,超越了包括DeepSeek-V3在内的多个知名模型。这一消息在AI界引起了广泛关注。
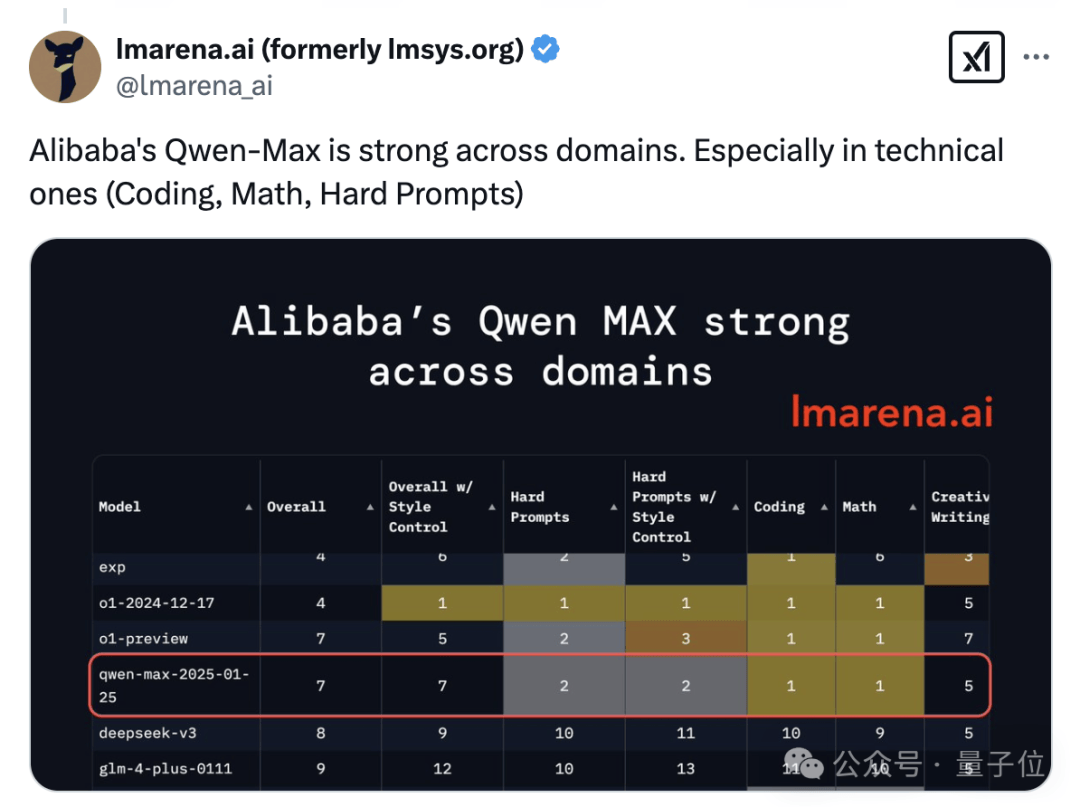
Qwen2.5-Max由阿里巴巴打造,此次在Chatbot Arena上的表现尤为抢眼。特别是在编程和数学方面,该模型展现出了非凡的能力,与满血o1和DeepSeek-R1并列第一。这一成绩不仅彰显了Qwen2.5-Max的技术实力,也为中国AI技术的发展赢得了国际赞誉。
Chatbot Arena作为全球顶级大模型的竞技场,其权威性和重要性不言而喻。该平台通过模型两两组队交给用户盲测的方式,根据真实对话体验对模型能力进行投票。Qwen2.5-Max能够在此次评选中脱颖而出,足以证明其在实际应用中的优秀表现。
Qwen2.5-Max在新开的网页应用开发WebDev榜单上也冲进了前十名,进一步展示了其全面的能力。不少网友在亲身使用后表示,Qwen2.5-Max的表现稳定且出色,甚至有人认为它很快就会取代硅谷的所有普通模型。
在具体单项能力方面,Qwen2.5-Max同样表现出色。在逻辑性较强的数学和代码任务中,该模型的成绩超过了o1-mini,与满血o1和DeepSeek-R1并列第一。在数学榜单上并列第一的模型中,Qwen2.5-Max是唯一一个非推理模型,这更凸显了其在数学领域的卓越表现。
Qwen2.5-Max在复杂提示词任务中也表现出色,与o1-preview并列第二。在仅限英文的情况下,该模型甚至可以排到第一,与o1-preview、DeepSeek-R1等顶级模型平起平坐。同时,Qwen2.5-Max的多轮对话能力也与DeepSeek-R1并列第一,长文本处理能力排行第三,超过了o1-preview。
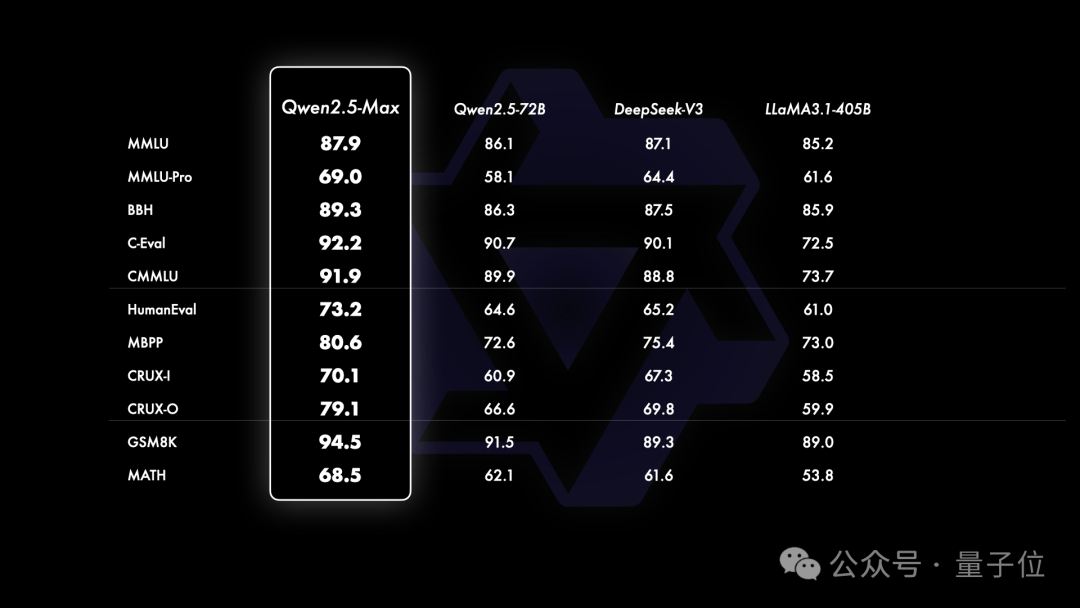
阿里巴巴在技术报告中还展示了Qwen2.5-Max在一些经典榜单上的表现。在指令模型对比中,该模型在Arena-Hard和MMLU-Pro等基准测试中,与GPT-4o和Claude 3.5-Sonnet处于近似或更高的水准。在开源基座模型对比中,Qwen2.5-Max的成绩也全面超过了DeepSeek-V3,并遥遥领先于Llama 3.1-405B。
Qwen2.5-Max上线后,吸引了大量网友前来实测。网友们发现,该模型在代码和推理等方面的表现尤为突出。例如,在让Qwen2.5-Max用Java写一个象棋游戏时,该模型不仅快速生成了简单易读的代码,还因为具备Artifacts功能,使得小游戏可以立刻开玩。在复杂提示词的推理问题上,Qwen2.5-Max也展现出了快速且准确的能力。

目前,Qwen2.5-Max已在Qwen Chat平台上线,可免费体验。企业用户也可以在阿里云百炼调用Qwen2.5-Max模型的API。感兴趣的用户不妨亲自上手实测,感受这款国产大模型的卓越魅力。