
随着人工智能领域的竞争日益激烈,中国的大模型市场正经历一场前所未有的变革。2024年,这一领域的分水岭已经显现,大厂与创业公司开始根据自身实力和目标,在技术、产品、商业化及生态建设上采取不同的战略路径。
在创业公司中,估值超过200亿人民币的五家大模型公司展现出不同的战略方向。百川智能专注于行业大模型,如医疗领域;月之暗面与MiniMax则优先发展C端产品与应用;而智谱与阶跃星辰依旧致力于AGI大模型的研发。相比之下,估值较低的Tier 2大模型公司早已转向垂直细分市场。
国内外多家大模型的发布,如Claude 3.5 Sonnet,标志着大模型性能的大幅提升,已能满足产品需求,并在多项测试中超越了GPT-4,OpenAI不再独领风骚。大模型正逐渐成为一种“电力”资源,为各行各业提供动力。一家专注于AI代码生成的创业公司透露,他们现在能够同时接入五个底层模型,根据产品需求灵活调用,如代码编写时选用Anthropic,指令遵循时则调用OpenAI。
在此背景下,大模型市场的未来商机被划分为三个层次:底层基座模型提供商(类似于发电厂)、中间云厂商(类似于国家电网)、以及上层AI软硬产品应用(如电冰箱、电风扇等电子产品)。由于资金、人才与资源的积累,无论是模型还是应用的创业公司,客观上只能选择两块战场,甚至只能专注于一个赛道。而基座模型训练的难度与资源要求极高,因此,创业公司的机会更多集中在应用层,包括AIGC软件应用和AI智能硬件。
尽管OpenAI不断发布新模型,但GPT-5的迟迟未公布,加上过去一年人才流失,模型训练技巧逐渐公开,下一代基座大模型的发展面临更多变数。推出下一代基座大模型的公司可能不再是OpenAI,也不再只有OpenAI。行业共识认为,具备顶尖人才团队、充足资金以及大量训练数据的公司,才有可能在这场竞争中脱颖而出。
国内大厂中,百度、阿里、字节在基座模型上具有领先地位,因此被认为有机会推出下一代基座大模型。然而,下一代基座大模型的训练成本仍然高昂,据估计,OpenAI训练一遍GPT-5的算力成本高达5亿美元。前零一万物首席架构师潘欣表示,大模型公司国内第一梯队一年要烧10亿美金,国际一年可能要50亿美金。资金实力已成为下一代大模型牌桌的重要门槛。
在海外,GPU价格下降,算力紧张程度缓解,这也反映出海外基座大模型玩家已收敛到头部大厂或创业公司。在国内,2023年大厂包揽模型、云与应用的态势尚不明显,但到了2024年,阿里将AI应用通义从阿里云分拆,开始在C端发力;字节重金招入人才,大力推广豆包;百度则在行业大模型与C端应用上共同发力,实现了一批场景的商业化验证。
百度、字节、阿里三家大厂在基座模型、云服务与应用层均有布局,这是他们押注大模型浪潮、应对不确定性的安全策略。在基座模型层,百度态度坚决,团队稳定;阿里、字节则在不同领域存在资源竞争与团队竞争。在云服务层,火山引擎绑定豆包与即梦,同时获取其他创业公司基座模型授权;百度重点服务头部国央企;阿里云则继续其投资凶猛的策略。在应用层,百度与阿里同时发力B端与C端,百度与行业头部客户共创行业大模型,C端则有AI搜索、文库、网盘等业务;阿里则以夸克搜索、通义App为主要抓手。字节则主要聚焦在多模态C端应用开发。
在竞争下一代基座模型的道路上,百度、阿里、字节展现出不同的优势。阿里采用生态打法,希望通过对外投资和模型开源聚集更多大模型玩家。字节则延续其一贯的土豪打法,结合算力储备和C端产品生态闭环,为多模态基座模型的训练提供支持。百度作为国内最早投入大模型的企业,在行业认知、模型技术积累和B、C端数据层面均领先。根据知识产权解决方案提供商Questel发布的《2024深度学习专利全景报告》,从2011年到2023年,百度在深度学习和大模型领域申请专利数位居全球第一。
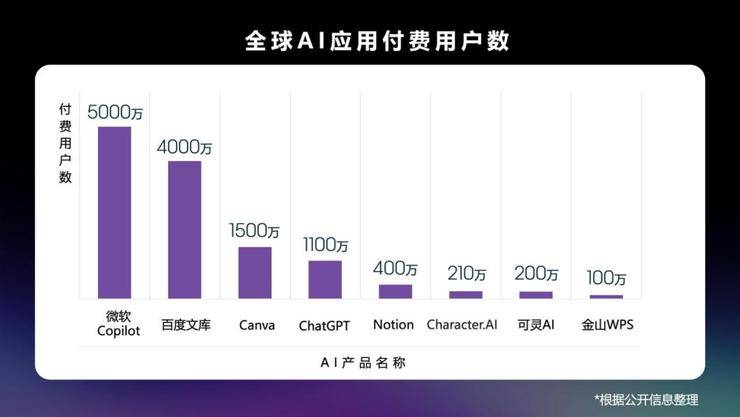
百度在C端AI应用上的发展尤为迅猛,以百度文库为例,其在国内的付费用户已突破4000万,AI功能的月活跃用户数已超过9000万,仅次于ChatGPT。百度在C端产品上的先发优势,不仅决定了市场份额,也形成了数据飞轮,促进了大模型的智能进化。百度还拥有丰富的B端与C端业务数据,包括搜索引擎带来的大规模中文数据、智能云积累的企业场景数据、C端应用产生的用户交互数据等,这些都将为下一代基座大模型的训练提供有力支持。



















