近日,一起由AI巨头OpenAI引发的网络爬虫事件引起了广泛关注。事件的主角是一家仅有7人团队的初创公司Triplegangers,他们的网站在无明显预警的情况下突然宕机,迫使CEO和团队成员紧急排查问题原因。
经过深入调查,Triplegangers的CEO发现,导致网站宕机的“罪魁祸首”竟是OpenAI的GPTBot。这款工具被OpenAI早年推出,用于自动抓取互联网上的数据。GPTBot对Triplegangers网站的“攻势”异常猛烈,据CEO描述,OpenAI发送了数以万计的服务器请求,试图下载网站上的所有内容,包括数十万张照片及其详细描述。
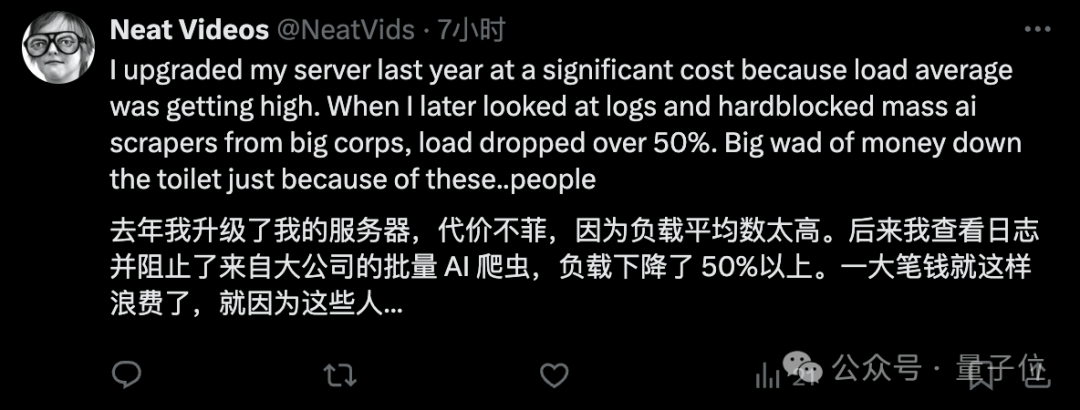
Triplegangers服务器日志:OpenAI机器人未经许可疯狂爬虫
Triplegangers的网站包含从实际人类模型扫描的3D图像文件,这些照片带有详细的标签,涵盖种族、年龄、纹身与疤痕、各种体型等信息,对于3D艺术家、游戏制作者等群体具有重要价值。CEO无奈表示,OpenAI的爬虫行为基本上构成了一场DDoS攻击,不仅导致网站宕机,还大幅增加了云计算服务(AWS)的资源消耗和开销。
这起事件引发了网友们的广泛讨论。有人认为GPTBot的爬虫行为并非简单的数据抓取,更像是“偷窃”的委婉说法。有网友甚至现身说法,表示在阻止了大公司的批量AI爬虫后,节省了一大笔费用。
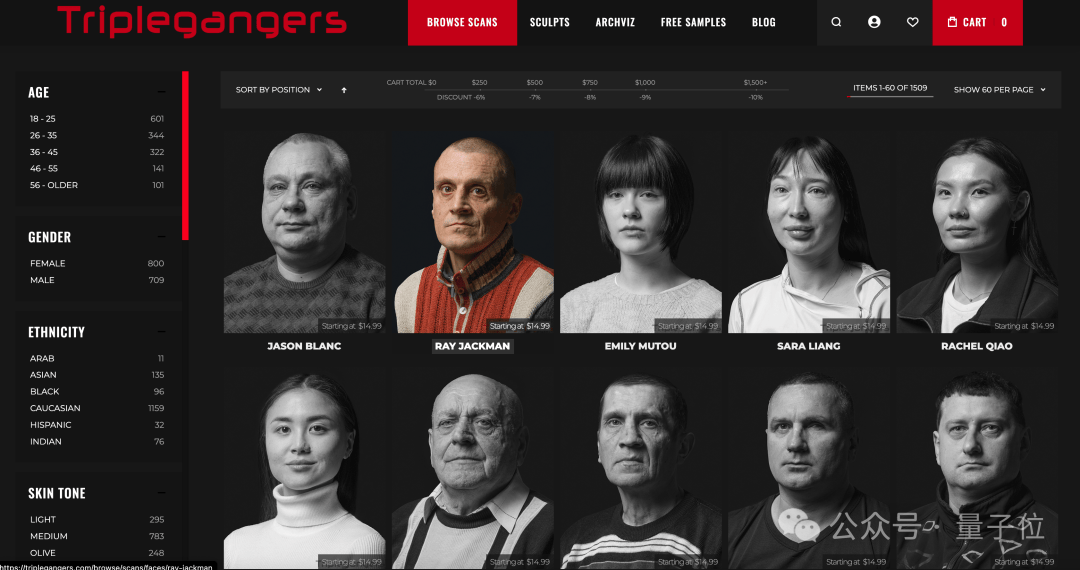
Triplegangers网站上的3D图像文件示例
那么,OpenAI为何会爬虫这家初创企业的数据呢?原因很简单,Triplegangers的数据属于高质量数据。Triplegangers的7名成员花费了十多年的时间,打造了号称最大的“人类数字孪生”数据库。然而,尽管Triplegangers网站上明确禁止未经许可的AI抓取,但显然并未起到任何作用。
问题的关键在于,Triplegangers没有正确配置Robot.txt文件。Robot.txt是网站用来告诉搜索引擎在索引网络时不要爬取哪些内容而创建的文件。如果网站不想被OpenAI爬虫,就必须正确配置Robot.txt文件,并带有特定标签,明确告诉GPTBot不要访问该网站。然而,即便立即正确设置了Robot.txt文件,也不会立即生效。
Triplegangers的CEO对此表示担忧,他认为如果一个网站没有正确配置Robot.txt文件,那么OpenAI和其他公司会认为他们可以随心所欲地抓取内容。这不是一个可选的系统,而是必须主动、积极地去配置和管理的。正因如此,Triplegangers在工作时间段网站被搞宕机,还搭上了高额的AWS费用。
为了防止类似事件再次发生,Triplegangers已经按照要求配置了正确的Robot.txt文件,并设置了Cloudflare账户来阻止其他AI爬虫。然而,CEO还有一个悬而未决的困惑,他不知道OpenAI都从网站中爬了些什么数据,也联系不上OpenAI。他担忧地表示,如果不是GPTBot“贪婪”到让网站宕机,他们可能还不知道它一直在爬取数据。

Game UI Database网站因OpenAI爬虫导致瘫痪的示例
事实上,Triplegangers并不是第一个因OpenAI疯狂爬虫导致宕机的公司。在此之前,还有Game UI Database等公司也遭遇了类似事件。这些事件都表明,AI公司在数据抓取方面的行为越来越疯狂,给小型网站带来了巨大的压力和风险。
AI公司之所以如此疯狂地“吸食”网络上的数据,主要是因为他们太缺用来训练的高质量数据了。随着AI技术的不断发展,对训练数据的需求也越来越大。然而,高质量的数据并不容易获取,因此AI公司不得不加快数据收集的速度。

AI训练数据价格示例
这起事件再次引发了人们对AI公司数据抓取行为的关注和讨论。如何平衡AI公司的数据需求和网站所有者的权益?如何确保AI公司在数据抓取过程中遵守法律法规和道德规范?这些问题都需要我们深入思考和探讨。