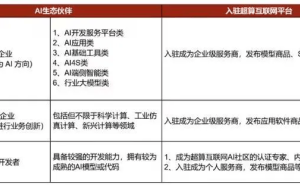
近期,中国人工智能领域再度掀起波澜,一家名为DeepSeek的新兴创业公司凭借其大模型DeepSeek-V3在业界崭露头角,引发了资本市场与媒体的广泛关注。这家源自杭州幻方量化公司的孵化项目,是否会成为又一颗璀璨的AI之星,尚需时间验证。

DeepSeek作为中国本土的人工智能企业,其发布的DeepSeek-V3模型的确在某些方面展现了非凡的实力。据悉,该模型在多项基准测试中取得了优异成绩,特别是在数学领域的math500和aime2024测试中,超越了包括llama3.1-405b、claude-3.5-sonnet以及备受瞩目的gpt-4o等国外主流大模型。在代码能力的codeforces基准测试中,DeepSeek-V3同样表现出色,分数高出国外主流模型约30分。DeepSeek-V3还采用了自研的mla(multi-head latent attention)和moesparse等架构,有效减少了显存占用,提高了计算资源的利用效率,训练成本仅为557万美元,相较于gpt-4o的1亿美元训练成本,显示出显著的成本优势。
然而,在对比DeepSeek与OpenAI这两大AI巨头时,我们不得不全面审视双方的优劣势。OpenAI作为人工智能领域的先行者,其GPT系列模型在自然语言处理领域拥有深厚的技术积累和广泛的认可度。特别是在推理能力和对复杂问题的处理能力上,OpenAI的o1、o3模型展现出了极高的水平,甚至在物理、化学和生物学等复杂学科的高难度基准任务上,o1模型的表现几乎与博士生相当,这无疑是OpenAI的一大亮点。
DeepSeek大模型的优势主要体现在成本效益和部分性能指标上。除了前面提到的训练成本仅为GPT-4o的十分之一外,DeepSeek-V3在特定领域的测试中超越了包括GPT-4o在内的众多国外主流模型,这无疑是其技术实力的体现。同时,DeepSeek在技术创新方面也取得了突破,自研架构和多项优化措施使得模型在显存占用和计算资源利用效率上有了显著提升。DeepSeek-V3还实现了100%开源,这有助于推动全球AI技术的发展和应用,降低技术门槛。
尽管如此,DeepSeek大模型在商业化应用和多模态、娱乐化方面仍存在一定的挑战。相比之下,OpenAI则凭借其深厚的技术积累、模型通用性强、推理能力突出以及丰富的应用生态,在全球范围内拥有广泛的用户基础和应用场景。然而,高昂的训练成本也成为制约OpenAI模型进一步发展和推广的瓶颈。
DeepSeek作为中国AI领域的新秀,其DeepSeek-V3模型在成本效益和部分性能指标上展现出了显著优势,但在商业化应用和多模态、娱乐化方面仍需进一步探索。而OpenAI则凭借其深厚的技术积累和应用生态,在AI领域占据了领先地位。未来,两者之间的竞争与合作,将共同推动全球AI技术的发展和应用。