杭州初创企业深度求索震撼发布低成本大语言模型DeepSeek V3
近日,杭州的一家初创企业深度求索(DeepSeek)在微信公众号上宣布了一项重大突破——全新的开源大模型DeepSeek V3。这一发布不仅伴随着53页详尽的技术论文,还揭示了该模型在多个评测中的卓越表现,瞬间引起了业界的广泛关注。
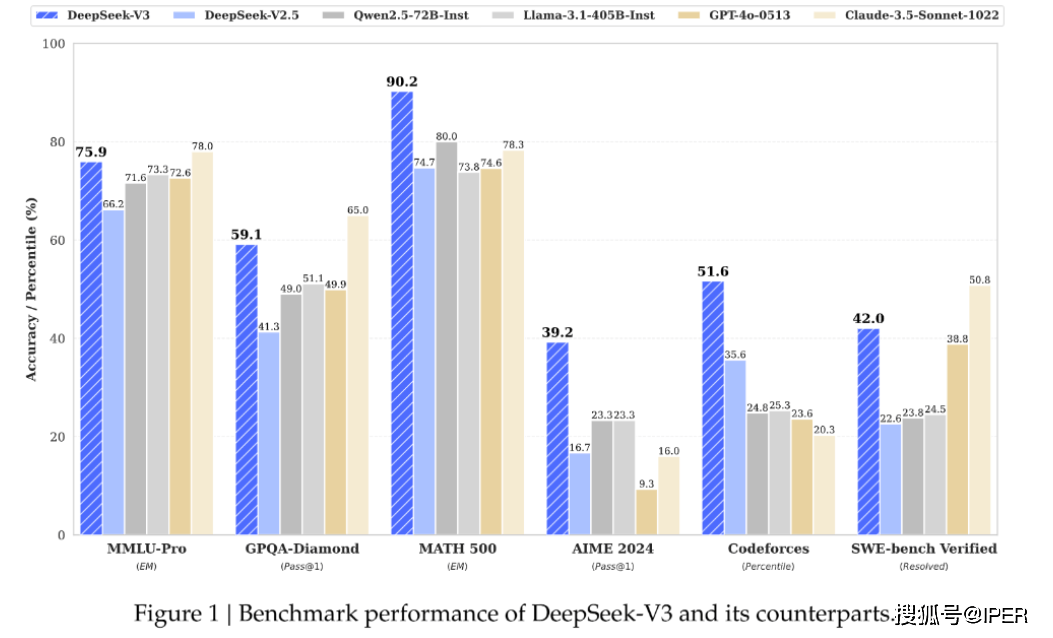
DeepSeek V3在百科知识、代码理解以及数学能力等多个方面均展现出了强大的实力。评测结果显示,它在这些领域的得分甚至超过了阿里云Qwen2.5-72B和meta的Llama-3.1-405B这两大开源模型,与世界顶尖的闭源模型GPT-4o及Claude-3.5-Sonnet相比也毫不逊色。特别是在数学领域,DeepSeek V3在美国数学竞赛(AIME 2024)和中国全国高中数学联赛(2024)中的表现尤为突出,遥遥领先其他所有开源和闭源模型。
然而,令人惊讶的是,DeepSeek V3的训练成本远低于业界预期。据深度求索公布的技术论文显示,该模型的训练总成本仅为557万6000美元,这一数字包括了前期的预训练、上下文长度扩展以及后续的训练阶段。相比之下,Llama-3.1的训练成本高达6.4亿美元,使用了1万6000张更先进的H100晶片,训练时间也长达3080万个GPU小时。而DeepSeek V3则仅使用了2048张英伟达特制的弱化版H800晶片,训练总时长仅为278万个GPU小时。
深度求索的这一成就得益于其自研的混合专家(Mixture of Experts)和多头潜在注意力(Multi-head Latent Attention)架构。在这一架构下,每个任务都会被自动分配给最擅长解决的专家模型,从而优化了算力资源的分配。这种创新性的方法不仅降低了训练成本,还提高了模型的性能。
据多家媒体和网民的实测,DeepSeek V3能够轻松应对一些简单的数学问题,如比较数字大小、计算字母数量等。在《华尔街日报》利用今年AIME的15道题进行的测试中,虽然OpenAI最新的o1模型在速度上更胜一筹,但DeepSeek V3在首次尝试时就能给出正确答案,这在文字题常常难倒AI程序的背景下显得尤为难得。
不过,也有网民发现DeepSeek V3在某些情况下会误称自己是ChatGPT,并生成与ChatGPT相同的笑话。有舆论质疑其是否使用了ChatGPT的输出内容进行训练,但分析认为这更可能是训练数据被污染所致。对此,深度求索尚未做出正式回应。
深度求索是量化巨头幻方量化在2023年4月创立的子公司。与众多获得大厂投资的初创公司不同,深度求索与科技巨头间并无直接关系。然而,这并没有阻止它在AI领域取得重大突破。事实上,幻方在大模型赛道的布局已久,深度求索原是幻方的AI研究部门,早在2021年就持有约1万个英伟达A100显卡,为训练大模型奠定了坚实的算力基础。
今年5月,创立刚满一年的深度求索就凭借开源模型DeepSeek V2在业界崭露头角。该模型在性能上与GPT-4 Turbo比肩,但价格却只有GPT-4的百分之一,因此被业界誉为“AI界的拼多多”。这一价格策略迅速引发了一场大模型价格战,迫使众多科技巨头纷纷跟进。
深度求索的创始人梁文锋表示,他们并没有有意成为行业的搅局者,只是希望让AI技术更加普惠、人人都能用得起。他认为,无论是API还是AI技术,都应该成为普及化的工具,为更多人所用。这一理念也体现在了DeepSeek V3的定价策略上,使得更多企业和个人能够享受到AI技术带来的便利。