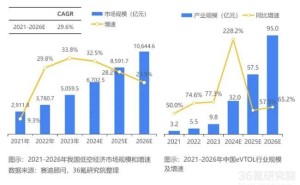
近期,关于人工智能大模型核心理论“Scaling Law”的起源,在国际网络上掀起了一场激烈的讨论。有最新观点指出,中国科技巨头百度可能早于OpenAI发现了这一关键规律。
据《南华早报》报道,题为《百度或先于OpenAI发现Scaling Law?AI领域争议再起》的文章指出,尽管美国在AI模型创新方面常被看作领航者,但最新的讨论揭示,中国在探索这些前沿概念方面可能更为领先。
“Scaling Law”被视为大模型发展的核心原则,它指出,随着训练数据和模型参数的增加,模型的智能能力也会显著增强。这一思想通常归功于OpenAI在2020年发表的论文《Neural Language Models的Scaling规律》。然而,OpenAI的这篇论文的合著者之一、前研究副总裁及Anthropic创始人Dario Amodei,在最近的一次播客访谈中透露,早在2014年,他在百度与吴恩达共同研究AI时,就已非正式地观察到了这一现象。

Dario Amodei表示,他们当时发现,随着提供给模型的数据量增加、模型规模扩大以及训练时间的延长,模型的性能出现了显著提升。这一观察结果在后来的GPT-1语言模型中得到了验证,并被广泛认为是AI大模型发展的基本法则。
不仅如此,行业内部人士还指出,关于Scaling Law的原始研究实际上源自百度2017年的一篇论文,而非OpenAI的2020年研究。meta研究员、康奈尔大学博士候选人Jack Morris在社交媒体上引用了一篇由百度硅谷人工智能实验室于2017年发表的论文《Deep Learning Scaling的实证可预测性》。该论文详细探讨了机器翻译、语言建模等领域的Scaling现象。
然而,这篇论文的重要性被长期忽视。OpenAI在2020年的研究中,虽然引用了百度研究人员2019年发表的论文《超越人类水平的准确性:深度学习的计算挑战》,但批评者认为,OpenAI选择性地忽略了百度2017年的研究,而这才是Scaling Law概念的真正起源。

有研究者强调,百度的早期研究为AI大模型的发展奠定了坚实的理论基础,并在2019年发布了第一代文心大模型,几乎与OpenAI处于同一时期。据《南华早报》报道,在百度世界大会2024上,百度宣布了新技术,旨在减轻图像生成中的幻觉问题,即生成误导性或事实不一致的图像。同时,百度透露,截至11月初,百度文心大模型的日均调用量已达到15亿次,相比一年前首次披露的5000万次,增长了约30倍。
这些进展表明,中国在大型模型方面的进步已获得了国际认可,进一步巩固了中国在全球AI领域的影响力和领导地位。