OpenAI GPT-5项目遭遇重重挑战,研发进度严重滞后
人工智能领域的巨头OpenAI正面临其最具挑战性的项目之一——GPT-5的研发困境。该项目,代号Orion,旨在成为ChatGPT技术的重大突破,然而,经过超过18个月的开发,其进度已显著落后于预定计划。

据知情人士透露,OpenAI已经至少进行了两次大型训练,每次都需要数月时间处理海量数据,但成果并未能充分证明其高昂成本的价值。据估计,仅六个月的训练成本就可能高达5亿美元。尽管GPT-5的性能有所提升,但这一进步幅度并未达到足以证明其高昂成本合理的水平。
OpenAI不仅面临着内部动荡,还遭受着竞争对手的不断挖角,顶尖研究人员频繁被开出高价挖走。这一困境进一步加剧了GPT-5项目的研发难度。
在Orion项目的挣扎中,OpenAI的研究人员意外发现了提升大型语言模型(LLM)智能的新途径:推理。他们发现,通过让LLM花费更多时间“思考”,可以解决一些未经过训练的困难问题。然而,这一方法也带来了额外的成本,因为需要生成对单个查询的多个答案,并进行深入分析。
The Wall Street Journal的报道指出,OpenAI的新人工智能项目进度滞后,费用巨大,且前景不明。有观点认为,世界上可能没有足够的数据使GPT-5足够智能。这一项目的正式名称为GPT-5,代号为Orion,旨在推动ChatGPT技术的重大进步。然而,至今尚未取得突破性进展。
OpenAI与微软的合作也备受关注。微软作为OpenAI最亲密的合作伙伴和最大投资者,原本预计在2024年中期看到新模型的发布。然而,由于项目进展缓慢,这一期望落空。
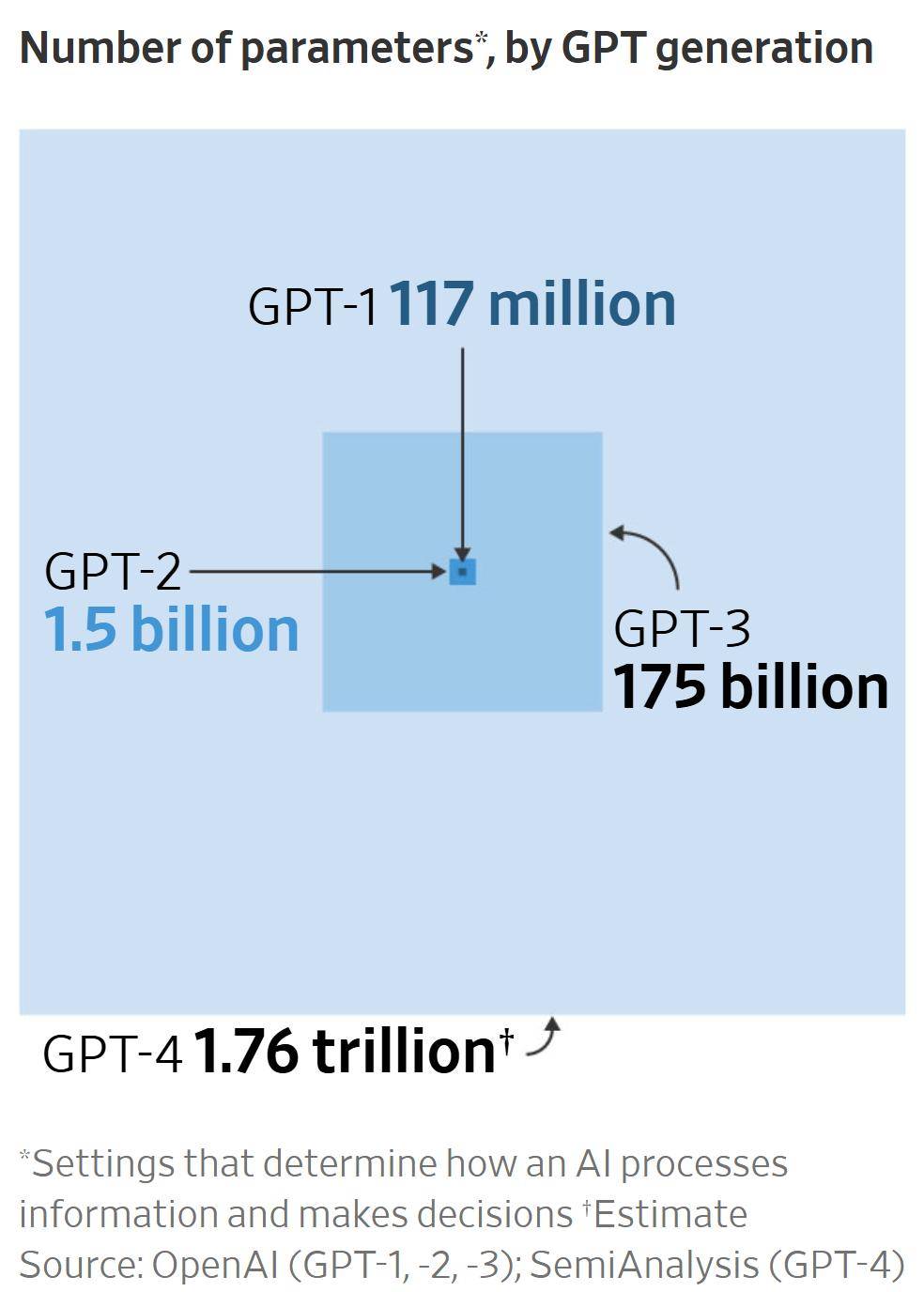
为了提升Orion的性能,OpenAI决定进行技术调整,并增加更多样化和高质量的数据。然而,公共互联网的数据并不足以满足需求,因此OpenAI开始从零开始创建数据。他们招聘人员为Orion编写新的软件代码或解决数学问题,并分享他们工作的解释,以增加新创建数据的价值。
然而,这一过程非常缓慢。GPT-4的训练数据估计为13万亿个标记,而新生成的数据远远无法满足这一需求。OpenAI还开始开发合成数据,即由AI创建的数据,以帮助训练Orion。但研究表明,AI为AI创建数据的反馈循环往往会导致故障或产生无意义的答案。
OpenAI的内部动荡也加剧了项目的困境。去年,CEO山姆·奥特曼被董事会突然解雇,引发了一系列人事变动。尽管他很快被重新任命为CEO,但公司的治理结构已经受到严重影响。今年已有多位关键高管、研究人员和长期员工离开OpenAI,包括联合创始人兼首席科学家伊利亚·苏茨凯弗和首席技术官米拉·穆拉提。
随着Orion项目的停滞,OpenAI开始开发其他项目和应用程序,包括精简版的GPT-4和可以生成AI视频的产品Sora。这导致了在新产品开发团队和Orion研究人员之间对有限计算资源的争夺。
尽管面临重重挑战,OpenAI的研究人员仍在努力寻找让LLM更聪明的新方法。他们正在探索推理模型的潜力,并希望将其与旧的方法结合起来,即增加更多数据。然而,这一策略是否有效尚不清楚。
在最近的一次TED演讲中,OpenAI的一位高级研究科学家强调了推理模型的优势。他指出,让机器人在一手扑克中思考更长时间可以获得显著的性能提升。然而,这一方法也带来了更高的成本。
尽管OpenAI面临诸多挑战,但他们仍在努力推进GPT-5项目的研发。然而,何时能够成功发布一个值得称为GPT-5的模型仍然未知。