
在人工智能领域的激烈竞争中,谷歌近期发布了一项重大更新,正式推出了Gemini 2.0,这一创新性的AI模型不仅大幅提升了任务处理能力,还首次实现了原生图像生成与多语言音频功能,标志着AI技术的新一轮飞跃。

就在同一天,OpenAI的“十二连发”活动进入第五天,但相比之下略显平淡,仅展示了ChatGPT与苹果Apple Intelligence的整合。而谷歌的发布会则因Gemini 2.0的震撼亮相而抢尽风头,一口气推出了三款基于新模型的AI Agent产品,进一步巩固了其在AI领域的领先地位。
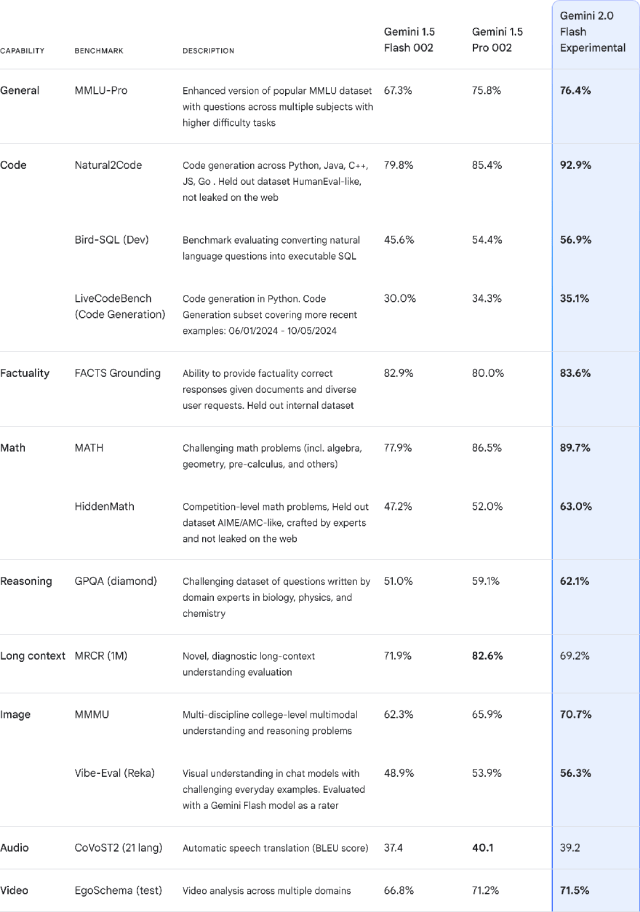
据谷歌DeepMind的CEO德米斯·哈萨比斯介绍,Gemini 2.0在保持成本效率、性能效率和速度的同时,整体性能提升了一个档次,甚至已超越了Gemini 1.5 Pro的水平。这一成果让谷歌团队倍感满意。
在官方数据对比中,Gemini 2.0 Flash在编程、数学、推理、图像、视频等领域的处理能力均显著优于前代产品。谷歌Gemini产品负责人图尔西·多希在发布会上表示,新版本不仅保持了快速响应能力,还新增了多项强大功能,性能提升显著,运行速度甚至比前代Flash模型快了一倍。
Gemini 2.0的最大亮点在于其“代理人工智能”(Agentic AI)功能,这种AI系统能够理解复杂的上下文,提前规划多个步骤,并在用户授权下采取行动。谷歌基于Gemini 2.0架构推出了三款AI智能体原型——Project Astra、Project Mariner和Jules,分别针对通用助手、浏览器操作工具和编程助手等应用场景进行了优化。
Project Astra作为升级版的通用AI助手,能够在多种语言之间自如切换,同时访问谷歌搜索、地图等工具并保持对话语境记忆。在实际演示中,该系统展现出了令人印象深刻的语言切换能力和实时信息获取能力。

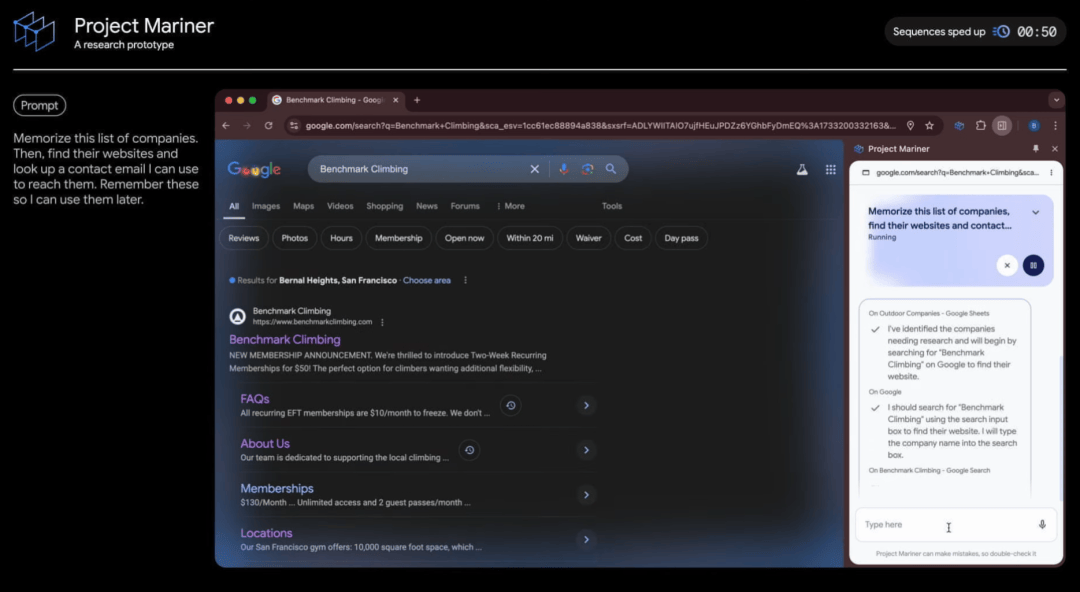
而Project Mariner则是一个探索人机交互未来的早期研究原型,能够理解和推理浏览器屏幕上的信息,并通过实验性的Chrome扩展程序完成任务。在WebVoyager单一代理基准测试中,Project Mariner取得了83.5%的成功率,创下了自主网页导航领域的新纪录。
针对软件开发者推出的Jules,则是一个能够自主修复软件错误并准备代码更改的AI编程助手。Jules能够直接集成到GitHub的工作流程系统中,分析复杂的代码库,跨多个文件实施修复,并准备详细的拉取请求,而无需持续的人工监督。这一创新在软件开发行业面临人才短缺的背景下显得尤为重要。

Gemini 2.0在音频和图像生成方面也取得了巨大突破,能够生成和修改图像,处理照片和视频,回答相关问题,还能用不同口音和语言的声音朗读文本。为了防止滥用,谷歌使用了SynthID技术对所有生成的音频和图像进行水印标记。
谷歌还正式向云服务客户开放了第六代张量处理单元(TPU)Trillium芯片,并在单个网络结构中部署了超过10万枚芯片。Gemini 2.0模型正是在Trillium上训练的。同时,谷歌推出了多模态实时API,帮助开发者构建具有实时音频和视频流功能的应用程序,进一步推动了AI技术的广泛应用。















