腾讯混元大模型近日正式推出了文生视频功能,这一功能早在11月底就已被“剧透”,并于12月3日正式上线。该功能现已集成于腾讯元宝App中,用户可以在AI应用板块的“AI视频”部分申请试用。对于企业客户,则可以通过腾讯云接入服务,同时API(应用程序编程接口)也已开放内测申请。
自OpenAI发布Sora以来,视频生成式大模型在国内外备受瞩目。在国内,快手和字节跳动在这一领域正面交锋,阿里云、MiniMax、美图等公司也蓄势待发。相比之下,腾讯混元的节奏并不算快,但它依然凭借强大的技术实力,成功推出了自己的文生视频功能。
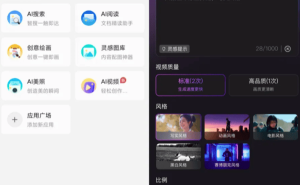
使用腾讯混元的文生视频功能非常简单,用户只需在提示框中输入一段描述,即可生成一段视频。这一功能与市场上类似的产品并无太大差异,但腾讯混元为用户提供了转场视频、多动作视频、超写实视频三种灵感提示,进一步丰富了用户的创作选择。
在实际体验中,用户可以选择写实、动画、电影、黑白、赛博朋克五种视频风格,以及五种不同的比例。高级指令部分的选择更为丰富,包括景别、光线、镜头运动等。其中,景别包括特写、近景等五种,镜头运动则包括固定镜头、手持摄影、拉近镜头等14种。这些选项为用户提供了极大的创作自由度。
根据腾讯提供的评测报告,腾讯混元视频生成模型与国内两个同类模型在持续时间、文本对齐、运动质量和视觉质量等方面进行了比较。结果显示,腾讯混元在文本对齐和运动质量方面表现优异,而在视觉质量方面则与GENN-3 alpha(Web)持平。尽管持续时间略短一秒,但腾讯混元凭借其在其他方面的优势,依然展现出了强大的竞争力。
腾讯混元多模态生成技术负责人凯撒介绍,混元基于与Sora类似的DiT架构,并在架构设计上进行了升级。这一升级使得混元视频生成模型能够更好地应对多个主体描绘,实现更细致的指令和画面呈现。同时,采用统一的全注意力机制,使得每帧视频的衔接更流畅,实现了主体一致的多视角镜头切换。通过图像视频混合VAE(3D变分编码器),模型在细节表现上有了显著提升,特别是在小人脸、高速镜头等场景。
腾讯在当天还宣布开源该视频生成大模型。该模型已在Hugging Face平台及Github上发布,包含模型权重、推理代码、模型算法等完整模型。企业与个人开发者可免费使用和开发生态插件。这一举措无疑将推动视频生成技术的发展和应用。
对于为何选择在此时上线文生视频功能,凯撒表示:“一个月前我们训练完了,现在上线水到渠成。”然而,业内人士更关心的是,该功能与同行相差的几个月时间差是否会对腾讯造成压力。对此,凯撒表示:“视频生成的成熟度还没有到外界想象得那么高,现阶段还是要自己做技术打磨。”
分析师李锦清在与记者交流时指出:“文生视频的实现难度更高,但商业空间更大。短期内竞争门槛不会马上建立,行业和企业有共性或特性的问题要解决,比如数据就是个槛。”这一观点也反映了当前视频生成技术面临的挑战和机遇。